OS의 가장 큰 특징은 multitasking을 지원하는 것입니다. 이를 위해 OS는 하드웨어 자원들을 여러 작업들에 잘 배분을 해야 하며 sheduling과 synchronization이 가능해야 합니다.
이런 OS 내부에는 다섯 개의 서브시스템이 존재합니다.
- Process management
- Address translation와 Memory management
- I/O Device management
- File subsystem
- Network subsystem
먼저 Process management에 대해서 알아보겠습니다. 프로세스는 OS에서 가장 중요한 개념으로 실행 중인 프로그램을 말합니다. 그래서 program in execution이라고 부르거나 또는 execution stream 이라고도 합니다. execution stream이란 실행 중인 instruction의 sequence를 말하는 것입니다.
프로그램과 프로세스가 어떤 차이가 존재하는지 알아보겠습니다. 스마트 폰에서 앱을 다운 받으면 실행 파일과 그 실행 파일을 deploy 하는데 필요한 여러 메타 데이터를 받게 됩니다. 여기서 메타 데이터를 제거한다면 다운된 실행 파일은 유용한 동작을 할 수 없습니다. 단순히 스토리지에 저장되어 있는 데이터로 볼 수 있는데 이것을 프로그램이라고 부릅니다.
프로그램은 굉장히 중요하지만 수동적인 존재로 볼 수 있습니다. 그러나 메타 데이터가 있는 상태에서 프로그램을 실행시키면 active 한 상태로 시간에 따라서 작업들을 처리하게 됩니다. 이러한 실행중인 프로그램을 프로세스라고 부릅니다.
실행 중인 프로그램, 즉 프로세스는 단순히 스토리지에 저장되어 있는 것이 아니라 메인 메모리에 적재되어 CPU를 통해 실행되고 I/O 디바이스로 입출력이 되는 상태입니다. 프로그램이 필요로 하는 자원은 스토리지 한 개이지만 프로세스는 메인 메모리, CPU, I/O 디바이스 등 다양한 시스템 자원을 필요로 합니다.
프로세스가 OS에서 가장 중요합니다. 왜 그렇냐면 컴퓨터 시스템은 내부적으로 볼 때 Synchronous system이지만 I/O 디바이스를 통해서 hardware interrupt를 받게 되면 프로세스가 별도로 Asynchronous 이벤트를 받아 처리하기 때문입니다. (컴퓨터 시스템의 Asynchronous한 부분을 프로세스가 만들어 주는 것)
프로세스는 실행 중인 프로그램이며 두 가지 하위 개념을 가지고 있습니다. exeuction stream과 process state입니다. 프로세스가 생성되면 process id를 가지게 되고 그 프로세스가 가지고 있는 정보들을 모아서 data structure를 유지하게 되는데 이걸 process control block이라고 이야기 합니다. 옛날에는 고정된 data structure인 array를 사용하여 PCB를 할당했기 때문에 사이즈가 많으면 할당하지 못하는 문제도 있었습니다.
프로세스가 작업을 수행하기 위해서 필요한 자원을 할당받으면 할당된 정보를 data structure로 만들어 OS가 관리하는데 이런 structure를 system context라고 부릅니다. 새로운 OS를 설계하게 된다면 제일 먼저 해야 할 일은 OS가 관리하게 될 프로세스의 state를 구현하고 data structure를 표현하는 것입니다.

프로세스에 대해 조금 더 알아보기 위해서 이전에 공부했던 multi-programming과 multi-tasking의 두 개념을 비교해 보겠습니다. multi-programming 같은 경우 OS 진화 과정 phase 1 마지막 단계에서 필요하게 되었습니다. CPU와 !/O 디바이스를 병렬적으로 수행하기 위한 하드웨어적 메커니즘은 다 구현했지만 Synchronous I/O를 하게 되었을 때는 CPU와 I/O의 연산을 병렬화 시킬 수 없었습니다.
이것을 병렬화하기 위해서 CPU가 Synchronous I/O 때문에 대기하고 있을 때 (입출력이 완료될 때까지 기다리고 있을 때), 메인 메모리에 다른 작업을 올려놓아서 CPU를 다시 작업하게 만들어야 했습니다.
multi-programming은 관심 있는 리소스가 메모리이고 multi-tasking은 관심 있는 리소스가 CPU입니다. 우리가 쓰는 모든 OS가 multi-tasking multi-programming 조합입니다. 메인 메모리에 active 한 프로세스들이 여러개 올라가 있고 CPU를 프로세스들이 주고 받으면서 multi-plexing을 하게 됩니다.
- multi-programming은 active한 작업이 메인 메모리에 여러 개 존재하는 경우
- uni-programming은 active한 작업이 메인 메모리에 한 개만 존재하는 경우
- multi-tasking은 CPU를 사용하는 작업들이 여러 개인 경우
- single-tasking은 CPU를 사용하는 작업이 한 개인 경우
single-tasking과 multi-programming은 조합 될 수는 없습니다. 하나의 작업만을 수행하기 때문에 여러 개의 active한 작업들이 존재할 수 없기 때문입니다. multi-tasking과 uni-programming의 경우 조합이 가능하지만 메인 메모리 존재하던 프로세스를 디스크로 보내고 다시 받아오는 형태로 굉장히 성능이 안 좋게 됩니다.(swap out 방법으로 예전에 하드웨어 자원 제약으로 쓰인 방법)

프로세스는 design time과 run time 관점으로 볼 수 있습니다. 지금까지 설명한 프로세스는 run time 관점으로 본 프로세스였습니다. 프로그램이 실행되어 프로세스가 되면 OS는 자원 할당을 하거나 프로세스를 관리하게 됩니다. 이것이 run time 플랫폼으로서의 역할을 수행하는 것입니다.
design time entity로서 프로세스를 살펴본다면 프로세스와 유사한 개념인 task와 thread에 대해서 알아야 합니다. run time entity로서 프로세스를 이야기할 때는 프로세스라고 부르고 design time entity로서 프로세스를 부를 때는 task라고 부릅니다.
C언어로 코딩해서 프로그램을 만들면 이 소프트웨어 결과물을 task들의 집합이라고 부를 수 있습니다.(프로그램은 일련의 task로 구성되기 때문에), 이때 프로그램을 프로세스로 만드는 작업을 해야 합니다. 즉 design time entity인 task를 run time entity인 프로세스로 mapping 하는 작업을 진행해야 합니다.
OS가 multi-tasking을 지원하기 때문에 design time에 나온 task를 run time entity인 프로세스와 1:1 mapping 시킬 수 있습니다. 그러면 concurrency에 관한 이슈들을 OS에게 전가할 수 있게 됩니다.

프로세스의 state는 3가지의 context로 구성됩니다.
- Memory context
- Hardware context
- System context
memory context란 프로세스가 수행되기 위해서 메인 메모리에 꼭 가지고 잇어야 되는 정보들을 이야기합니다. OS가 프로세스에게 메모리 영역을 할당할 때 segment라고 하는 기본 단위를 사용합니다. 우리가 사용하는 머신은 폰 노이만 머신이기 때문에 데이터와 instruction에 해당하는 코드가 다 메인 메모리에 존재해야 합니다.
그렇기 때문에 프로그램을 구성하는 instruction들의 집합이 code segment에 들어가 있어야 합니다. 프로그램이 적재될 때 할당되는 global variables는 data segment에 할당이 됩니다. local variable을 담는 stack을 제공해 주는 stack segment도 필요합니다. 그리고 dynamic memory allocation과 같은 동적 메모리 할당을 위해서 공간이 하나 더 필요한데 그곳을 heap segment라고 합니다. memory context는 이렇게 code segment, data segment, stack segment, heap segment, 4가지 요소로 구성됩니다.
hardware context는 CPU 레지스터나 I/O 컨트롤러 레지스터, MMU 레지스터와 같은 메모리 소자들 입니다. data structure는 프로세스가 할당받아 사용하는 resource, 스케줄링 정보, process id들로 이루어지며 모두 모아 system context라고 부릅니다.

여기서의 state는 프로세스의 state가 아닙니다. 프로세스 state는 그 프로세스가 메모리 소재에 어떤 값을 가지고 있는가를 보는 것이고 여기서 state는 프로세스가 어떤 상태에 있는지를 나타냅니다. 프로세스의 생성, 소멸까지의 state transition을 보기 위해서 아래 사진과 같은 다이어그램을 사용합니다.

각 state를 표현하며 edge를 통해 transition을 표현하는 다이어그램입니다. 바탕화면에 어떤 아이콘을 두 번 클릭하면 그 프로그램이 실행되는데 이때 OS가 프로그램을 메모리에 적재하고 CPU를 할당해 줍니다. 메모리 적재 후 실행에 필요한 모든 자원을 확보하고 있지만 CPU를 확보하지 못한 상태가 ready state입니다. ready state는 CPU를 받기 위해서 대기하는 queue입니다. (run queue, ready queue)
ready state에서 CPU를 할당받으면 running state가 됩니다. CPU가 한 개라면 OS가 관리하는 프로세스 중 running state에 있는 프로세스는 한 개만 존재합니다. run queue나 ready queue에 프로세스를 넣는다는 것은 PCB 자료구조를 넣는다는 것입니다.
A 프로세스 수행 중 A 프로세스가 synchronous 하게 된 경우 B 프로세스에게 CPU를 양보해 주고 대기하는 상태가 waiting state입니다. B 프로세스 작업이 다 끝나면 waiting state에 있는 A 프로세스를 확인하고 ready state로 보내게 됩니다. (다시 scheduling을 받게 하고 우선순위가 높으면 running state로 가는 절차를 밟아야 합니다.) 프로세스들은 waiting state에 들어온 이유에 따라 여러 개의 waiting queue에 따로 보관해야 합니다.
running에서 ready state로 가는 프로세스들이 존재하는데 그 이유는 CPU protection에 있습니다. 너무 오래 CPU를 차지하는 경우 타이머로부터 interrupt를 받게 되어 OS의 handler가 프로세스를 다시 ready state로 변경합니다.
- 프로세스가 자발적으로 CPU를 양보하는 것을 non-preemptive scheduling이라고 합니다.
- 강제로 뺏겨서 가는 경우는 preemptive scheduling 이라고 합니다. (반드시 inerrupt가 일어나야 변경이 됩니다, 여기서는 timer interrupt)
( + 추가 설명) 유저 모드에서 코드가 돌다가 preemptive scheduling이 일어나서 ready queue로 프로세스를 보내려면 커널 모드로 모드 체인지가 일어나야 하며 스케줄러 코드가 실행돼야 합니다. 유저 모드에서 커널 모드로 변경되려면 interrupt mechanism이 필요하기 때문에 running state에서 ready state로 프로세스를 옮기려면 interrupt가 필요하다는 것을 알 수 있습니다. 여기서는 timer interrupt가 일어나서 위 동작들이 진행된 것입니다.
정리하자면 OS는 PCB라는 data structure를 시스템 이벤트에 따라 각 state queue로 옮겨주는 연산을 해줍니다. 프로세스도 여러 state로 옮겨주는데 이것이 바로 scheduling입니다.

process scheduling 이란 multi-tasking 환경에서 active 한 프로세스들이 CPU를 multiplexing 하는 방법입니다. 즉 여러 active한 프로세스들이 CPU를 어떤 방식으로 공유할지 선택해 주는 작업을 해줍니다. 이때 scheduling에 몇 가지 규칙이 존재합니다.
첫 번째는 scheduling은 공정해야 합니다. 여러 많은 프로세스들이 어느 정도 진행할 수 있도록 CPU를 받게 합니다.
두 번째는 Protection입니다. 여러 프로세스들이 CPU를 공유하다 보면 CPU안의 레지스터와 같은 리소스를 공유하게 돕는데 이때 다른 프로세스가 레지스터 값을 망치지 않게 보호해야 합니다.
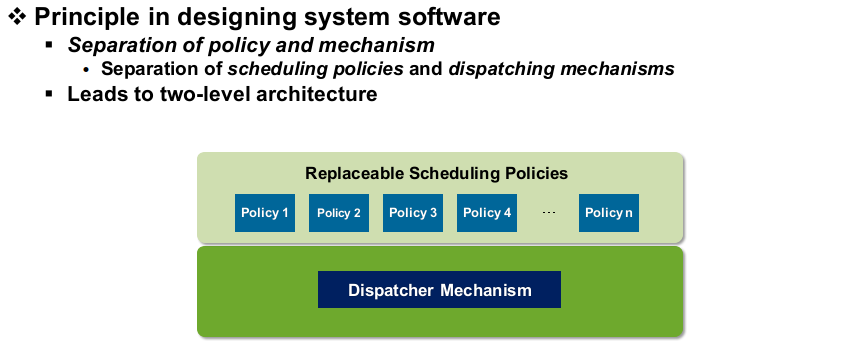
OS는 two level로 구현이 됩니다. 아래 layer는 여러 개의 scheduling policy들이 공유하는 메커니즘으로 dispatcher mechanism이라고 부릅니다. 위 layer에는 여러 개의 sheduling policy들이 필요에 따라 호출되어 사용될 수 있는 구조로 이루어져 있습니다.

Dispatcher는 OS의 가장 안쪽 깊은 곳에 있는 무한 루프라고 보면 됩니다. 동작은 간단하게 과거에 선택한 프로세스를 실행하다 resheduling이 발생하면 실행을 멈추고 멈춘 프로세스의 context를 안전하게 이동시킵니다. 그 이후 다음 프로세스를 선택한 뒤 필요한 context를 가져와 실행하는 것을 반복합니다.

single processor에서는 유저 코드를 실행시키다가 dispatcher 코드로 CPU 제어권을 넘기고 scheduling을 하는 방식으로 진행이 됩니다. dispatcher 코드 실행은 scheduling을 하기 때문에 커널 모드에서 실행이 돼야 합니다. 그러면 유저 모드에서 커널 모드로 모드 체인지가 일어나야 합니다.

OS의 핵심적인 부분인 스케줄러, 동기화 제어, I/O 서브시스템 등을 커널이라고 합니다. 커널은 커널 모드에서 사용하는 커널 함수와 인터럽트 서비스 루틴으로 구성된 일종의 프로그램으로 passive entity입니다. (라이브러리)
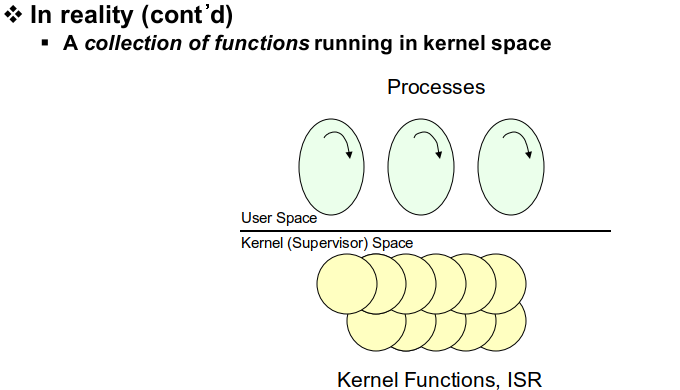
위쪽은 유저 모드에서 돌아가는 프로세스들의 공간이고 밑은 커널 모드입니다. 유저 프로세스가 커널 함수를 호출하는 것을 시스템 콜이라고 하는데 이때도 interrupt가 발생하여 모드 체인지가 일어납니다. (커널 함수는 커널 모드에서 실행되기 때문에)

유저 프로세스가 실행되다 read()라는 시스템 콜이 호출되면 시스템 콜 interrupt가 발생합니다. 그 이후 커널 모드로 진입하게 됩니다. 이렇게 모드 체인지가 발생하더라도 실행 중인 process id는 유저 모드에서 중단된 process의 id를 따라갑니다. 현재 수행 중인 모드가 유저 모드인지 아니면 커널 모드인지의 차이가 발생하는 것뿐입니다. (context 변경은 일어나지 않는다.)

system call과 function call의 차이는 커널 모드에서 실행되는가 유저 모드에서 실행되는가입니다. function call 같은 경우 유저 모드에서 실행되며 유저 스페이스에 존재하는 유저 레벨 스택에 적재가 되지만 system call 같은 경우 커널 스페이스에 있는 커널 레벨 스택에 적재가 됩니다.
모든 프로세스는 유저 레벨 스택과 커널 레벨 스택 이렇게 2개의 스택을 가지게 됩니다. 이런 스택들도 context라고 부르는데 process의 context를 생각하시면 안 됩니다. 인터럽트 서비스 루틴은 커널 모드에서 실행되는 커널 레벨 스택이 필요합니다.
Context Switching

프로세스가 중단되고 다른 프로세스를 실행시킬 때 컨택스트 스위칭이 발생합니다. 이때 컨택스트를 안전한 장소로 옮기는 block data move 명령은 굉장히 비싼 명령입니다. 그렇기 때문에 중단이 풀렸을 때 다시 실행되게 하는 최소한의 정보만 옮겨야 합니다.
우선 새로운 프로세스가 CPU 레지스터를 overwrite 하기 때문에 중단되는 프로세스가 가지고 있던 CPU 레지스터 값을 이동을 시켜야 합니다. 메인 메모리가 작다면 메인 메모리에 보관 중인 segment들도 디스크로 swap out 할 수도 있습니다.
컨택스트 스위칭이 구현되려면 interrupt와 stack manuplation이 필요합니다. 컨택스트 스위칭이 일어날 때의 내부 동작에 대해서 알아보겠습니다. 인털 프로세서는 스택 바닥이 하이 메모리에 있고 로우 메모리를 향해 거꾸로 자라니 현재 스택 포인터 레지스터는 top element를 가리키고 있습니다. 이때 interrupt가 발생한다면
- 마이크로 프로세서는 실행 중인 instruction을 중지합니다.
- 다음 instruction의 주소와 기억해야 할 레지스터 값들을 스택에 저장합니다.
- interrupt vector table에서 해당 interrupt service routine의 주소를 얻어옵니다.(interrupt를 발생시킨 소스의 IRQ number를 통해 검색하여 주소를 찾습니다.)
- interrupt service routine의 주소로 점프를 합니다. (이 과정들이 inerrupt handling입니다.)
- interrupt service routine안에서 rescheduling을 통해 OSPCBCur 글로벌 변수에 다음에 진행할 프로세스의 PCB를 저장합니다.
스위칭이 일어날 때 스택에 push 하는 값 중에는 PSW(process State Word)의 mode bit 값도 존재합니다. 모드 체인지가 일어나 커널 모드로 변경되기 때문에 이전의 모드도 저장을 해둬야 합니다. interrupt service routine도 스택에 CPU 레지스터 값을 push 하여 기존 유저 모드에서 사용하던 레지스터 값들을 스택에 대피시키는 동작을 합니다.
요약하자면 컨택스트 스위칭은 interrupt service rotine에서 일어나며 전반부에서는 현재 수행 중인 프로세스의 CPU 레지스터를 전부 세이브하고 후반부에서는 rescheduling 된 프로세스에 CPU 레지스터 콘텍스트를 복원하는 작업을 진행합니다. return 시 중단했던 프로세스의 수행이 resume 됩니다. (컨택스트 스위칭 메커니즘을 수행하는 것은 dispatcher입니다.)
Process Creation

full-filedged OS에서 프로세스를 생성하는 방법은 2가지가 있습니다. 첫 번째가 OS가 프로세스의 컨택스트를 하나하나 만들어서 프로세스를 생성하는 것이고 두 번째는 유닉스 또는 리눅스 OS에서 사용하는 방법으로 기존에 생성했던 프로세스를 그대로 복제해서 새로운 프로세스를 만드는 fork() 시스템 콜 방법입니다. 처음에는 어떤 방법을 사용하던지 id가 0인 프로세스를 만들어야 합니다.

process id가 0인 프로세스를 만들 때 OS는 코드와 데이터를 executable file에서 불러오고 수행에 필요한 빈 런타임 스택과 힙 세그먼트를 만듭니다. PCB와 같은 data structure를 할당받고 초기화시킨 다음 프로세스를 ready queue에 넣습니다.
Fork

Fork는 기존에 생성되어 있던 프로세스를 복사해 새로운 프로세스를 만드는 과정으로 생성된 프로세스를 child process, 원본 프로세스를 parent process라고 부릅니다. parent process에서 fork system call을 실행하는 시점이 cloning이 진행되는 지점입니다.
fork system call을 하게 되면 software interrupt가 발생하여 sys_fork() 커널 함수가 실행이 됩니다. sys_fork() 함수는 자신을 부른 parent process의 실행을 중단시키고 snapshot을 통해 parent process context를 저장합니다. 그리고 snapshot 정보를 복사해서 child process 생성합니다. 이때 child process는 process id를 제외한 나머지를 그대로 복사하여 생성합니다. 그 이후 child process를 ready queue에 넣고 다음 sys_fork()는 return 합니다.
이렇게 1개의 parent process를 process id만 바꿔서 복제해 진행하는 경우 모든 프로세스들이 동일한 executable 파일을 실행하는 문제가 발생하게 됩니다. 이런 문제를 해결하기 위해서 child process 내부에서는 exec() system call을 사용합니다. (fork() system call과 exec() system call은 항상 같이 사용됩니다.)
exec()은 child process를 위한 새로운 executable 파일을 찾고 기존 data segment를 overwrite 합니다. 새로운 프로그램 코드를 실행할 수 있게 만들어주는 동작을 진행하게 됩니다.
Process life cycle in Unix

fork-exec mechanism을 도식화한 다이어그램입니다. 처음에는 parent가 fork()를 진행합니다. snapshot을 바탕으로 child process를 생성하고 child process 내부에서는 exec() system call을 실행합니다. 이 system call은 child process가 실행시킬 executable code를 file system에서 읽어 메인메모리에 저장하는 역할을 합니다.
exec() 이후에는 exit() system call을 통해 실행을 종료합니다. parent process는 fork()를 호출하고 return을 받은 다음 다른 작업을 진행하다 wait()을 호출하게 됩니다. wait()은 방금 fork()된 child process가 실행이 종료될 때까지 자신을 block 하는 system call입니다.
Family tree in Unix

이 사진은 fork(), exec()을 진행하여 생성된 Unix의 Family tree입니다. Process id가 0인 프로세스는 부팅 과정에서 제일 먼저 생성되는 프로세스입니다. 이 프로세스는 OS가 완전히 부팅하게 되면 fork()를 통해 process id가 1인 init process와 process id가 2인 pagedaemon process를 생성합니다. init process는 지금 부팅하고 있는 컴퓨터 시스템이 서버로서 해야 되는 기능들을 설정합니다. (다른 서버 소프트웨어를 fork()하는 등)
init process가 fork() 하는 ttys는 터미널 라인 초기화 프로세스로 모든 터미널 라인을 초기화시키고 유저가 해당 터미널 라인에 로그인할 수 있도록 컴퓨터 시스템을 준비해 주는 작업을 합니다.
이 ttys process는 getty process를 fork()합니다. getty process는 터미널 라인을 모니터링하면서 유저가 key stroke을 누르면 login process를 fork()하여 진행할 수 있도록 만들어 줍니다. login process는 유저 아이디와 패스워드를 입력받아 유효한 값인지 확인하고 터미널을 열어주는 역할을 합니다.
로그인이 완료되면 Unix operating system을 사용할 수 있게 됩니다. 유저가 Unix operating system을 사용하려면 명령어를 입력했을 때 해당 명령어를 해석하고 구동시켜주는 소프트웨어가 필요한데 이것을 shell이라고 부릅니다. (login process가 shell process를 fork() 한 것)
Shell example
for(;;) {
cmd = readcmd();
pid = fork();
if(pid < 0){
perror("fork failed");
exit(-1);
} else if(pid == 0) {
// Child – Setup environment
if(exec(cmd) < 0) perror(“exec failed”);
exit(-1); // Exit on exec failure
} else {
// Parent – Wait for command to finish
wait(pid);
}
}
이 shell code는 실행하면 로그아웃하기 전까지 무한 루프를 돌게 됩니다. 루프를 돌며 프롬프트 사인을 내보내서 유저의 커맨드 라인을 입력받는 역할을 합니다.
첫 번째 라인은 유저가 제공한 커맨드 라인을 line-by-line으로 읽어오는 작업을 진행합니다. 읽은 커맨드는 cmd라는 변수에 저장을 합니다. 유저가 작성한 커맨드 라인은 제 3자가 작성한 executable file로 실행하려면 fork()를 통해 child process를 생성하고 exec() 과정을 거쳐야 됩니다.
fork()는 커널 모드에서 실행되며 모드 체인지가 일어난 다음에 커널 내부에서 sys_fork() 함수를 실행시켜 주는 system call입니다. fork()는 일반 함수처럼 유저에서 return value를 제공하는데 이 값을 저장하는 공간이 pid입니다. fork()가 만들어준 child process id가 pid에 저장되게 됩니다.
이 pid 값이 0보다 작을 경우 fork() system call에 오류가 발생한 것으로 paraent process의 수행을 termination 시켜야 합니다. 0이 아닌 경우 else 내 코드를 실행하는데 여기서는 wait() system call을 호출합니다. pid(child process)의 수행이 종료될 때까지 해당 코드 진행을 멈추는 것입니다. (이 프로세스에서 fork()를 진행했으므로 parent process로 볼 수 있기 때문)
우리가 커맨드 라인을 입력하면 그다음에 프롬프트 라인이 잠시 멈추는데 이때 child process가 수행되는 것입니다. ctrl + c를 누르면 바로 프롬프트 라인이 진행되는데 이것은 child process를 강제 종료했기 때문입니다.
생성된 child process의 동작
생성된 child process는 fork()를 통해서 parent process를 모두 복사하기 때문에 위의 sehll example 코드를 그대로 복사해 진행합니다. 그래서 child process도 위 코드를 실행하는데 어디서부터 실행하냐면 parent process가 자기를 생성해 준 그 위치부터 진행하게 됩니다.
parent process의 코드 진행 순서도 복사되어서 pid에 fork() 값을 return 해주는 시점부터 진행하기 때문에 두 번째 pid 값을 받게 됩니다. 여기서 fork() system call은 parent process에게는 생성한 child process의 id 값을 return 하지만 child process에게는 0을 return 합니다.
그 이후 else if 문 내부 코드를 실행하게 되는데 여기에 exec() system call이 존재합니다. 유저가 작성한 executable 파일의 path 이름인 cmd를 입력으로 받아 parent로부터 받은 segment를 전부 overwrite를 하여 새 커맨드를 수행할 수 있는 환경을 만들어 줍니다.
fork(), exec()의 대한 추가 내용
1. original fork() mechanism의 단점은 무엇인가?
2. 이러한 단점에도 불구하고 사용하는 이유는 무엇인가?
3. 왜 아직도 fork()와 exec() mechanism을 사용하는가?
1. original fork() mechanism의 단점은 무엇인가?
이렇게 3가지 내용에 대해서 알아보겠습니다. 첫 번째 fork(), exec의 단점은 매우 비싸다는 것입니다. parent process의 컨택스트를 child process의 컨택스트로 복사하는 것이 굉장히 많은 양의 memory to memory move operation이 필요하기에 비용이 크다는 것입니다.

memory conetxt를 중심으로 parent process는 kernel data structure로 PCB를 가지며 메모리에는 각 code segment, data segment, stack segmetn, stack segment, heap segment가 존재합니다. 각각의 segment의 base address를 PCB에 process table 형태로 유지되고 있습니다.
cloning을 진행하면 child process는 각각의 segment를 할당받고 모든 데이터 콘텐츠를 복사합니다. 굉장히 많은 memory to memory copy operation의 형태의 deep copy를 진행하여 매우 비쌉니다. deep copy는 데이터 블록에 있는 모든 데이터 컨텐츠를 전부 다 copy 하는 것으로 이것이 original fork(), exec()의 단점입니다.
비싼 비용을 치르고 segment를 복사하더라도 다른 응용프로그램의 executable file을 실행하기 위해서 segnment를 다 버리고 exec()을 통해 실행할 파일의 segment를 overwrite 합니다.
2. 이러한 단점에도 불구하고 사용하는 이유는 무엇인가?
초창기 unix operation은 코드 사이즈가 2000~5000 줄 밖에 되지 않는 단순한 OS 시스템이었습니다. 이 때문에 많은 OS 시스템의 기능이 빠져있었는데 대표적인 것이 프로세스와 프로세스 간의 통신하는 inter process communication (IPC) mechanism이 빠져있었습니다. 프로세스 간의 데이터를 전달해서 사용하는 과정이 필요합니다.
Image processing을 예로 들자면 이미지 센서가 캡처한 영상 데이터를 받아서 전처리하고 다시 필터 프로세스로 넘겨 후처리 하는 프로세싱 단계를 거쳐야 합니다. 이런 알고리즘을 구현하려면 프로세스 간의 데이터를 전달하는 기능이 필요합니다. 초기 unix os의 경우 IPC mechanism이 없었지만 IPC를 했어야 했습니다.
두 프로세스가 데이터를 주고받으려면 shared memory가 있어야 합니다. 하지만 모든 프로세스는 중첩되지 않으며 0번 주소부터 시작하는 자기만의 logical address space를 가지고 있었습니다. 서로 중첩되는 shared memory가 없었기에 shared memory를 통한 IPC의 구현은 어려웠습니다.
이 시기에는 성능이 중요한 시기가 아니었기 때문에 성능을 좀 희생하더라도 공유된 공간을 만들어주는 것이 필요하다고 생각했고 그것이 파일입니다. 메모리는 서로 공유하지 못하더라도 디스크의 파일은 서로 공유할 수 있었기 때문에 어떤 프로세스가 파일로 데이터를 기록하면 다른 프로세스가 파일에서 그 데이터를 읽어오는 형식으로 느린 방법이지만 IPC 동작을 수행할 수 있었습니다.
여기서 또 하나의 문제가 생기는데 파일을 통해 IPC를 진행하려면 다른 프로세스가 파일의 이름을 알아야 합니다. 이 파일의 이름을 알려면 IPC가 필요함으로 recursive 한 문제가 발생합니다. 그래서 최소한 파일의 이름은 자연스럽게 공유하며 파일을 통해서 data transfer만 진행하는 것이 초기 unix os를 설계한 사람들의 의도일 것으로 예상이 됩니다.
ipc_proc()
{
fd = open("./fifo_pipe", O_RDWR);
pid = fork();
if(pid > 0){
//Parent – write data to the pipe
write(fd, data, size);
} else if(pid == 0) {
// Child – read data from the pipe
read(fd, data, size);
}
}
파일 이름을 공유하는 데 사용한 방법이 fork() mechanism으로 위 코드가 ipc_proc()이라고 하는 샘플 코드로 parent process와 child process가 IPC 하는 과정을 구현한 것입니다. if문 내부 코드는 parent process가 실행을 하고 else if문 내부 코드를 child process가 실행합니다. fd(file description)를 parent가 작성하고 child가 읽는 방식으로 데이터를 읽고 씁니다.
child는 fd를 fork()를 통해 복사하여 얻습니다. parent와 child의 relationship을 fork()를 통해 맺어주면서 많은 기초 정보들을 공유할 수 있게 됩니다. 지금은 memory management 기술이 발전을 해서 logical address space가 다른 두 프로세스 간의 공유메모리 매핑이 가능합니다.
하지만 unix 프로그래머들이 프로세스를 생성할 때 fork(), exec()을 사용하는 방법이 계속 유지가 되어서 unix를 계승한 os들은 fork(), exec()을 아직 사용하고 있습니다. window os 같은 경우에는 fork(), exec()을 사용하지 않습니다.
3. 왜 아직도 fork()와 exec() mechanism을 사용하는가?
초기 unix os에서 fork()를 진행하면 parent에서 child로 deep copy가 일어났습니다. 현재에는 데이터 콘텐츠의 베이스 주소만 복사해 오는 shallow copy를 진행하고 있습니다.

copy를 할 때 데이터들은 그대로 두고 parent process의 segment base address만 복사하여 가져옵니다. 4개의 포인터만 복사해 오니 비용이 적은 operation입니다. 이 방법을 통해서 기존 deep copy를 진행하는 fork()의 overhead를 극복할 수 있습니다.
이 방법에도 단점이 존재하는데 child process도 segment를 write 하는데 이렇게 되면 두 프로세스가 값을 수정하기에 오류가 발생할 수 있습니다. 그래서 read-write가 일어나는 segment의 경우 공유가 불가능 하지만 code segment와 같이 read만 하는 경우 공유가 가능합니다.
다른 segment의 경우 copy-on-write mechanism을 통해서 해결을 했습니다. 이 방법은 공용 세그먼트가 있을 때 parent나 child 둘 중 한 곳에서 write를 하는 경우 그때 data segment의 값을 복사하여 두 개의 private data segment를 만들어 주는 방법입니다. (lazy copy operation으로 실제적인 copy를 하지 않고 있다가 필요한 시점에만 진행하는 방법)
위 내용들을 통해서 3번째 질문에는 다음과 같은 답을 할 수 있습니다. shallow copy와 copy-on-write 때문에 fork(), exec() mechanism의 비용이 초기와 다르게 저렴하다.
Process termination
process creation은 child의 의지와 무관하게 parent에 의해서 생성이 되었지만 termination의 경우 한 가지 방법으로 발생하는 것이 아니라 child가 실행이 완료되었을 때 exit() system call을 통해서 스스로 종료하거나 child가 아닌 다른 곳에서 종료시키는 abort, 이렇게 두 가지 방법이 있습니다.

exit() system call은 process가 생성될 때 할당받았던 자원들을 다 반환하는 동작을 합니다. 모든 리소스를 다 반환하면 한 가지 부작용이 발생할 수 있는데 parent가 wait()을 호출하기 전에 child가 먼저 exit()을 해버리면 parent는 termination 여부를 확인하지 못하고 계속 대기하게 됩니다.
그래서 exit()할 때 parent가 wait()을 하지 않았다면 parent에게 termination을 했다고 알려줄 정보만 남기고 나머지 리소스는 다 반환하는 형식으로 과거에 exit 된 child를 parent가 확인할 수 있도록 해줘야 합니다. child가 exit을 했는데 parent와 동기화가 되지 않아서 최소한의 정보를 가지고 있는 상태를 좀비 상태라고 합니다. 프로세스 상태로 ready state, running state 말고 좀비 상태가 추가되게 됩니다.
두 번째 방법은 unix os에서 프로세스 간에 관계를 나타내주는 패밀리 트리가 생성되는데 이 트리에서 어떤 프로세스가 종료된다면 그 아래 child process나 decendent process가 함께 종료되게 됩니다. 우리가 쉘에서 여러 child process를 만들어서 실행하다 쉘에서 로그아웃을 하게 되면 그 child process의 동작들도 다 종료시키는 abort 시그널이 발생하는 모습을 생각하시면 됩니다.
'CS > Operating System' 카테고리의 다른 글
| 6. 리소스(Resource) (0) | 2023.10.24 |
|---|---|
| 5. 멀티 쓰레딩(Multi Threading) (2) | 2023.10.17 |
| 3. 스택(Stack) (2) | 2023.10.01 |
| 2. System bus, Duel mode (0) | 2023.09.30 |
| 1. OS의 발전 과정 (0) | 2023.09.23 |