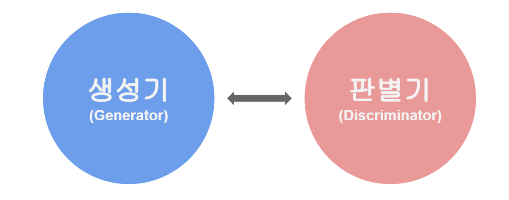
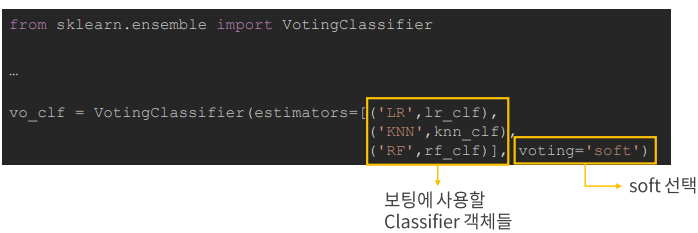
GAN은 생산적 적대 신경망(Generative Adversarial Network)의 약자이며 비지도학습(Unsupervised Learing) 입니다. Generator가 위조 데이터를 만들면 Discrminator가 진짜인지 가짜인지 구분을 하여 판별기를 속일 수 있도록 Generator를 훈련해야 합니다. Discriminator는 실제 데이터로 훈련을 진행해야 합니다. Loss function $min_Gmax_D \, V(D,G) = E_{x ~ p_{data}}(x) [log \, D(x)] + E_{z~p_z}(z)[log(1 - D(G(z)))]$ 실제 데이터 분포에서 샘플링한 데이터 x와 임의의 데이터 분포에서 샘플링한 데이터 z D(x)는 1이 나오도록 학습하고 D(z)는 0이 나오도..