OS는 대부분 high level language로 구현되어 있으며 OS가 포팅된 하드웨어와 무관하게 구현될 수 있지만 반대로 타겟 하드웨어 특성에 굉장히 민감한 부분도 존재합니다. 이 부분은 context switching을 담당하는 부분입니다. context switching은 CPU에 있는 레지스터들의 속성을 이용해서 조정하는 일들을 많이 진행하기 때문에 그렇습니다.
MMU라는 하드웨어를 기반으로 동작을 하는 Memory manageement 부분도 하드웨어와 밀접하게 관련이 있는 부분입니다. 그렇기에 하드웨어가 발전하게 되면 OS의 memory management 부분도 같이 변화해야 합니다.

페이징 매커니즘을 공부하면서 몇 가지 단점에 대해서도 알아봤습니다. 메모리 액세스의 성능이 저하되는 문제는 TLB cache를 통해서 해결했기 때문에 고려하지 않아도 됩니다. 여전히 남아있는 문제는 프로세스 당 유지해야 하는 페이지 테이블의 사이즈가 크다는 것입니다.
현재 사용하는 CPU의 경우 32bit address space가 아닌 64bit address space를 가지는데 64bit address space로 표현되는 공간은 어마어마하게 크기 때문에 페이지 테이블의 사이즈도 증가하게 됩니다.
이 문제는 하드웨어 발전으로 해소할 수 있습니다. 메모리 사이즈가 커지고 저렴해지니 페이지 사이즈를 키워 페이지 테이블 크기를 줄이면 OS가 관리하는 프로세스 당 페이지가 줄어드니 관리 오버헤드가 줄어들게 됩니다. 그리고 페이지당 TLB 커버리지를 높여 hit ratio를 증가시킬 수 있습니다.

위 문제와 마찬가지로 2의 64승의 address spave를 가지게 되므로 4K짜리 페이지를 두게 된다면 64K짜리 페이지 테이블이 됩니다.

버츄얼 메모리 매니지먼트 시스템은 OS에서 굉장히 중요한 역할을 하게 되니 메인 메모리 매니지먼트를 진행하는 부분과 융합되게 됩니다. 대표적으로 File I/O와 버츄얼 메모리 매니지먼트가 결합된 mmap system call이 존재합니다.

mmap이라고 하는 것은 메모리 맵의 약자로 디스크 스토리지에 존재하는 파일을 피지컬 메모리에 그래도 매핑시켜 파일 I/O 없이 메모리 I/O만으로 파일을 액세스 하는 동작을 할 수 있습니다. (File space를 메모리에 매핑시키는 것)
이렇게 매핑을 시키기 위해서는 file을 대표하는 파일 디스크립터(File descriptor)가 필요합니다. 이 파일 디스크립터는 매핑하려고 하는 베이스 위치를 offset 파라미터로 받아 유저 프로세스의 버츄얼 메모리 주소를 표현하는 addr과 1대 1로 매핑시킵니다.
mmap은 파일을 유저 프로세스의 로지컬 어드레스 페이지에 매핑이 됩니다. 그래서 파일의 영역이 유저 프로세스의 한 페이지가 되어 페이지 테이블의 entry를 차지하게 됩니다. 이 페이지의 페이지 프레임에는 디스크에 있는 파일의 컨텐츠가 복사되어 들어가 있습니다.
로지컬 페이지를 통해 피지컬 메모리를 액세스하여 read/write를 진행하면 실제 파일이 수정되는 효과를 얻을 수 있습니다. (파일 액세스를 하지 않고 파일 콘텐츠를 읽어올 수 있다.), 다른 프로세스들도 똑같이 매핑을 하면 동일한 파일 콘텐츠를 공유할 수 있습니다. (프로세스들이 exe 파일을 공유하는 것을 쉽게 구현할 수 있음, 실제 리눅스에서는 mmap을 통해서 프로세스 간 코드 페이지를 공유함)

만약 mmap을 사용하지 않고 과거 방식대로 디스크에 액세스한다면 위 사진의 왼쪽 그림과 같이 동작합니다. 유저 프로세스에서 로지컬 어드레스에 파일을 읽고 쓸 페이지를 할당하고 이 페이지를 통해서 디스크의 파일을 액세스 하면 파일의 콘텐츠가 커널 메모리인 버퍼 캐시로 들어오게 됩니다.
유저가 파일 컨텐츠를 읽으면 버퍼 캐시(이미 메인 메모리 들어온 상태)로 카피된 파일 콘텐츠가 다시 유저 페이지로 카피가 됩니다. 이 방법은 전통적인 방법으로 파일을 액세스 하면 memory to memory copy가 한번 더 일어나며 다른 프로세스가 콘텐츠를 읽고자 한다면 또 다른 피지컬 프레임으로 읽어와야 하는 문제가 생깁니다. (파일 콘텐츠 개수가 늘어남 = 버전 관리가 어려워짐)
mmap을 사용하면 1개의 데이터 블록으로 해결되지만 전통적인 방법을 사용할 시 커널과 유저 메모리에 3개의 데이터 블록을 사용해야 해결이 가능합니다.

malloc을 통해 유저 스페이스에 굉장히 큰 메모리 오브젝트를 요청할 때 malloc 내부에서는 mmap system call이 호출 됩니다. 이렇게 사용되는 mmap을 이름이 없는 메모리 세그먼트를 할당한다고 하여 anonymous mmap이라고 부릅니다. 파일을 유저 프로세스의 로지컬 어드레스에 매핑할 때는 이름을 가진 entity를 매핑하기에 non-anonymous mmap이라고 부릅니다. 이 두 mmap을 구분하여 사용하기 위해서는 mmap의 flag 파라미터를 세팅해줘야 합니다.

이번에는 address translation이 어떻게 일어나는지 알아보겠습니다. address translation이나 다른 OS의 기능들은 대부분은 페이지 테이블을 사용하여 구현됩니다. 위 사진 초록색 부분에서 mmap을 호출한다고 해보겠습니다. p1 = mmap() 의 경우 파일로 매핑시키지 않는 annoymous mmap으로 가정해 보겠습니다.
annoymous mmap을 통해서 return value의 메모리 세그먼트 시작 주소를 받아왔습니다. 초록색 박스 옆에있는 그림에서 왼쪽 column은 버츄얼 어드레스 스페이스이고 오른쪽 coulmn은 피지컬 스페이스의 모습입니다. 아직 동작이 수행되지 않아 두 column 다 비워져 있는 것을 알 수 있습니다.
annoymous mmap을 실행하면 첫 번째로 버츄얼 어드레스 스페이스에 세그먼트라고 부르는 메모리 영역이 할당됩니다. 이 영역은 used page로 변경되지만 페이지 테이블의 entry를 할당받지 못한 불완전한 페이지입니다. 이 메모리 세그먼트의 100번지에 1이라는 값을 쓰는데 이때 이 주소에 대해 address translation이 일어납니다.
address translation을 할려고 했지만 페이지 테이블 entry가 없기 때문에 페이지 폴트가 발생합니다. 이를 통해서 페이지 프레임과 페이지가 생성되고 entry를 만들 수 있게 됩니다. 마지막 3번째 단계는 munmap으로 할당받은 모든 버츄얼 메모리와 페이지 테이블 entry를 반납하여 초기 상태로 돌아갑니다.
이렇게 mmap을 통해서 사용자가 원하는대로 로지컬 세그먼트를 만들 수 있고 잘 매핑하면 다른 프로세스와 세그먼트를 공유할 수 있습니다. 페이지 테이블은 용량을 많이 잡으니 anonymous mmap은 필요하지 않을 때는 할당하지 않는 방식
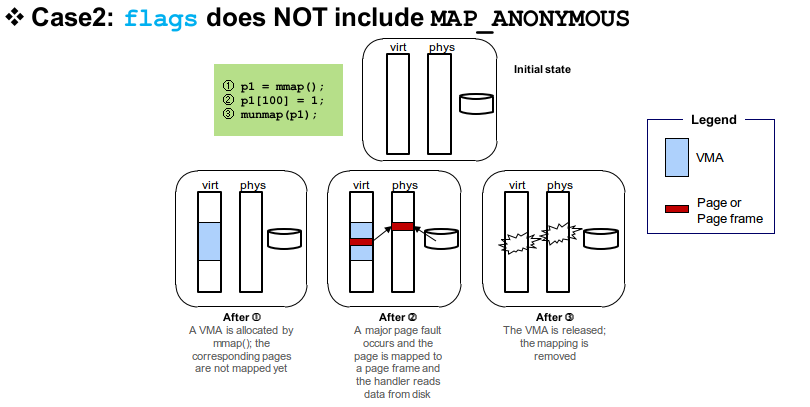
non-anonymous mmap의 예시입니다. 이번에는 버츄얼 어드레스 스페이스, 피지컬 어드레스 스페이스, 디스크가 사용됩니다. non-anonymous mmap을 진행하게 되면 스토리지에 있는 파일의 블록과 버츄얼 메모리 영역이 서로 매핑이 되게 됩니다. 이곳을 액세스 할 시 페이지 폴드가 발생하며 페이지 테이블의 entry와 페이지, 페이지 프레임을 잡고 파일의 데이터 콘텐츠를 읽어옵니다.

이번에는 페이징 메커니즘을 사용할 때 생기는 large page table 문제를 해결하는 방법에 대해서 알아보겠습니다.첫 번째 hierarchical page table은 페이지 테이블을 다단계로 만드는 것이고 두 번째 hashed page table은 페이지 테이블을 해싱하는 기법입니다. 마지막 방법 inverted page table은 하나의 페이지 테이블만 사용하여 이전과 반대로 피지컬 프레임 넘버를 입력받으면 프로세스 아이디와 로지컬 페이지 넘버를 출력합니다.

세 가지 방법 중에서 hierarchical page table이 가장 보편적으로 사용됩니다. hierarchical page table의 특징은 로지컬 스페이스 상에 존재하는 sparse 한 공간을 활용하기 위해서 딱 필요한 만큼의 페이지 테이블 entry를 준다는 것과 페이지 테이블을 조각내어 어떤 곳에서든 할당받을 수 있다는 것입니다.
아무 데서나 할당을 받기 위해서 페이지 테이블들의 조각들을 가지고 있는 페이지들의 주소를 인덱스로 만듭니다. 인덱스 테이블을 통해 페이지 테이블 entry를 얻을 수 있습니다.

예제를 통해서 더 자세히 알아보겠습니다. 예제의 머신 address는 32bit로 4byte를 word로 합니다. 이중 22bit를 페이지 넘버로 사용하며 한 페이지의 사이즈는 1kb입니다. 페이지 테이블 entry의 사이즈는 한 워드로 4byte가 됩니다. 하나의 페이지 테이블 entry가 4byte이고 2의 22승 개의 페이지가 있으니 최대 페이지 테이블 사이즈는 16MB가 됩니다.

이 16MB를 페이지 단위로 쪼개서 담으려면 16K 개 만큼의 페이지가 필요합니다. 이 16K 개의 페이지는 위 사진 속 빨간 박스 안에 있는 column 형태로 표현되어 있습니다. 이 페이지들을 seond level page table이라고 부릅니다. seond level page table을 구성하는 페이지들은 시스템상 아무 곳에나 scatter 될 수 있기 때문에 액세스 하려면 인덱스가 필요합니다.
16K만큼의 페이지들을 index로 표현하기 위해서는 14bit가 필요합니다. 페이지 넘버의 22bit 중 14bit가 entry안에 있는 페이지를 표현하는 인덱스로 사용됩니다. 이 14bit 인덱스를 index to first-level page table이라고 부릅니다. 나머지 8bit는 페이지 테이블의 1kb 페이지에 들어 있는 256개의 entry를 인덱싱하는데 사용합니다.
즉 22bit의 페이지 넘버를 가지고 14bit는 페이지를 구성하는 페이지 인덱스로 사용되며 나머지 8bit는 그 해당 페이지 안에서 페이지 테이블 entry의 인덱스로 사용됩니다.
이렇게 계층적 페이지 테이블을 구성하면 페이지 테이블이 피지컬 메모리에 연속적으로 존재하지 않아도 되며 사용하지 않는 페이지들을 담고 있는 페이지 테이블 조각들을 버릴 수 있게 됩니다.
'CS > Operating System' 카테고리의 다른 글
| 24. Device Drivers (2) | 2024.01.31 |
|---|---|
| 23. I/O Device 관리 (1) | 2024.01.30 |
| 21. Trashing and Working set (1) | 2024.01.27 |
| 20. Demand Paging (2) | 2024.01.26 |
| 19. Memory Management Mechanism (1) | 2024.01.25 |