
파일 시스템이란 루트 디렉터리부터 모든 서브 디렉터리까지 계속적으로 연결된 트리로 볼 수 있습니다. (사용자의 관점에서는 디렉터리와 파일들의 계층적인 구조), OS 입장에서는 스토리지 디바이스 위에 포맷된 볼륨으로 볼 수 있습니다. (스토리지 디바이스 위에 저장된 디스크 블록의 집합체)

위에서는 파일 시스템이 데이터 컨텐츠를 저장한다는 측면에 대해서만 설명했지만 사실 파일 시스템은 더 많은 일을 합니다. 우선 저번에 공부했듯이 모든 로지컬/피지컬 리소스에 대한 name space를 제공해 줍니다. (해당 리소스에 쉽게 접근할 수 있도록 window에서는 C:\window\home 이런 식으로 제공)
그리고 파일 시스템은 파일과 디렉토리에 할당된 디스크 블록을 표현해 주기 위한 다양한 데이터 구조를 가지고 있습니다. 어떤 데이터 구조는 메인 메모리에 캐시 형태로 존재할 수 있습니다. (정리하자면 데이터를 저장하거나 쉽게 접근할 수 있게 해 주거나 관리하기 쉬운 형태로 변환해 주는 것)
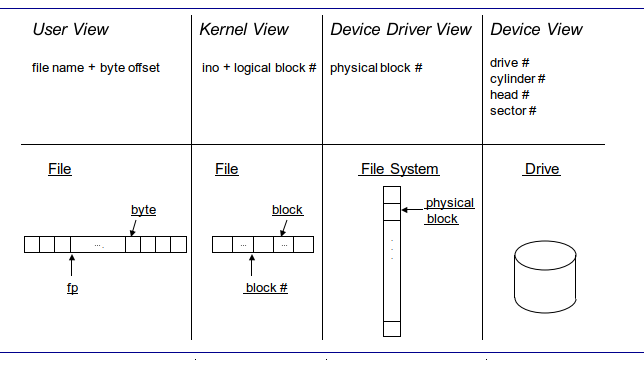
파일이라는 개념은 user view와, kernel view, device view가 각각 다릅니다. 하지만 결국에 디스크 스토리지에 있는 데이터를 액세스 한다는 점에서 drive view로 OS가 매핑을 시켜줘야 합니다. (파일은 다양하게 표현이 되는데 결국 하나의 드라이브로 매핑을 시켜야 한다.)
유저가 파일 데이터를 액세스 하기 위해서는 file name을 통해 접근하여 lseek system call을 사용해 원하는 바이트를 읽어오면 됩니다. 유저가 파일 안에 있는 특정 바이트를 읽어 오려면 file name과 그 바이트의 offset이 필요합니다. 위 사진에서 fp는 file point입니다.
커널은 string으로 구성된 symbolic file name을 사용하지 않습니다. inumber라는 인덱스를 통해 파일 데이터를 액세스 합니다. 또한 커널은 파일을 바이트 시퀀스가 아닌 블록 시퀀스로 인식합니다. logical block number와 index number를 통해 액세스를 하는데 logical block number는 단순히 inode로 표현되는 파일 안에 들어있는 블록 중 몇 번째를 의미하는지 알려주는 번호입니다.
유저 레벨에서 사용하던 byte offset이 사라졌는데 그 이유가 커널에서 바라봤을 때 I/O의 파일 시스템에서 단위가 블록이기 때문에 한 바이트를 읽어오려고 해도 블록 전체를 읽어야 하기 때문입니다.
디바이스 드라이버는 파일을 구별하기보다는 스토리지 디바이스의 볼륨 전체를 고려합니다. 블록들을 linear array로 만들어 스토리지의 섹터에 매핑되는 형식의 피지컬 한 엔티티가 됩니다. 즉 0, 1, 2, 3 이렇게 리니어 하게 부여된 피지컬 블록 넘버가 디바이스 드라이버가 바라보는 블록의 주소가 됩니다. (inumber + logical block number = 몇 번째 피지컬 블록이냐로 표현됨)
디바이스는 스토리지로써 3차원적인 구조를 가집니다. 실린더, 헤드, 섹터 넘버가 있어야 데이터를 액세스 할 수 있으며 여기서 섹터 넘버가 디바이스 드라이버가 바라보는 블록과 일대일 매핑이 됩니다. 추가적으로 파일 시스템이 어떤 드라이브에 있는지를 표현하는 드라이브 넘버가 필요합니다.

조금 정리해 보자면 user view에서 byte offset이 kernel view에서는 해당 byte를 포함하는 logical block number가 되는 것이고 logical block number는 그 파일 안에서 몇 번째 블록인가를 알려주는 번호입니다. 이 logical block number는 다시 그 파일 시스템을 담고 있는 스토리지 디바이스의 physical block number로 매핑이 됩니다.
이와 같은 매핑을 제공해 주기 위해서는 OS에서는 상당히 복잡한 model transformation 모듈로 구성이 되며 서로 간 interaction이 가능해야 합니다.
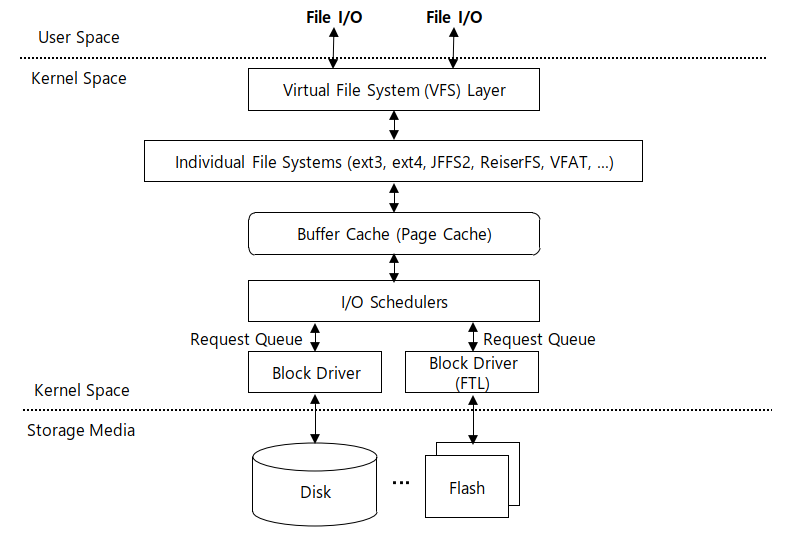
하드웨어 부분에서 disk와 flash는 속성이 다른 디바이스로 각기 다른 디바이스 드라이버를 가지고 있습니다. 이런 디바이스 드라이버들은 하드 디스크와 플래시 메모리의 고유한 특정들을 추상화시키고 나머지 커널 스페이스 모듈에게 두 하드웨어를 구별할 수 없을 정도의 편리한 인터페이스를 제공해 줍니다.
이 나머지 모듈 중에 제일 첫 번째 부분이 I/O 스케줄러입니다. multi programming, multi tasking을 하기 때문에 다수의 프로세스가 디바이스 디스크로 가는 명령 (read / write)를 이슈하게 됩니다. 이런 명령들이 여러 개 존재하니 정리해서 처리해야 하는데 이때 사용되는 것이 queue입니다. (I/O request queue, I/O command queue)
queue에서 대기하는 entity들의 실행 순서를 결정해 주는 것이 스케줄링입니다. 디스크 I/O 문제에 대한 스케줄링이니 I/O 스케줄링이라고 이야기합니다. 이 I/O 스케줄러 위에는 buffer cache라는 스토리지의 디스크 블록을 캐싱하는 모듈이 존재합니다. 대부분의 I/O operation은 이 cache에서 cache hit이 발생하여 실제 스토리지로 이동하는 단계까지는 가진 않습니다. (disk cache 모듈이 스토리지 액세스를 상당히 줄여줍니다, 리눅스에선 page cache라고도 부릅니다.)
이 cahce가 I/O scheduler 위에 존재하는데 이유는 실제 cache miss가 발생했을 때만 storage access command, request로 변경되어 I/O request queue로 들어가기 때문입니다. hit이 난다면 I/O scheduler가 해줄 일이 없습니다. 이 buffer cahce 위에 파일 시스템이 존재하게 됩니다.
modern operation system안에는 여러 개의 파일 시스템이 공존합니다. 이전에는 하나의 OS에 한 개의 파일 시스템만이 존재했습니다. 하지만 유저들이 여러 OS를 사용하다 보니 다양한 파일 시스템을 경험하게 되었고 결과적으로 하나의 OS에서 다수의 파일 시스템을 지원하여 유저들의 편의성을 높여주게 되었습니다.
이런 다수의 파일 시스템을 unify 시켜주는 레이어가 필요한데 이걸 그 위에 존재하는 virtual file system(VFS) 모듈이 진행해 줍니다.

하드웨어 수준에서 유저 수준까지의 파일 시스템의 구성과 각각의 역할에 대해 알아봤는데 이제는 설계자 관점에서 파일 시스템을 설계할 때 고려해야 될 부분에 대해 알아보겠습니다.
mass storage device에 액세스 한다는 것은 굉장히 긴 delay를 발생시킵니다. 그래서 이 delay를 짧게 만들거나 유저들이 인식하지 못하도록 숨기는 것이 중요한 요소가 됩니다. 그래서 OS 설계의 첫 번째 design goal은 어떤 파일 액세스 패턴에 대해서도 average access time을 최소화하는 것입니다.
파일을 액세스 할 때 패턴은 크게 3가지로 나눌 수 있습니다.
1. Sequential access
2. Random access
3. Keyed access
Sequential access

순차적 액세스는 간단히 말하면 우리가 책을 읽을 때처럼 1페이지 첫 줄을 시작으로 그다음 줄, 그 다음 장까지 계속 이어서 읽는 것입니다. 실제로 많은 애플리케이션의 경우 파일을 시퀀셜 하게 읽습니다. 컴파일러의 경우 소스 코드를 line by line으로 sequential 하게 읽는 경우를 생각해 보시면 됩니다.
sequential access는 빈번히 나타나는 패턴으로 빠른 access time을 제공해 주는 것이 중요합니다.
Random access

Random access는 파일 콘텐츠를 읽을 때 임의의 데이터 블록으로 가서 읽고 그다음에 또 다른 데이터 블록으로 이동해서 읽는 방식으로 진행됩니다. virtual memory management에서 메인 메모리 크기 제약으로 인해 swap area라는 스토리지에 페이지들을 저장하는데 이 상황에서 page fault가 발생하면 그 페이지를 swap area에서 읽어오게 됩니다.
이 경우 swap area의 임의의 위치에 저장되어 있는 페이지를 찾아와 읽어오는 일을 하는데 이런 방식의 access가 random access가 됩니다. random access가 가능하려면 읽고자 하는 데이터 블록들의 인덱스가 잘 정리되어 있어야 합니다. 실제로 database management system에서 데이터 콘텐츠가 블록 단위로 나눠 저장이 되어있고 액세스에 도움을 주는 index table이 별도로 존재했습니다.
Keyed access

Keyed access는 파일이 키를 가지고 있는 레코드들의 집합체로 구성된다는 전제를 기반으로 합니다. 어떤 search key가 주어지면 그 search key에 매핑이 되는 레코드를 읽어오는 방식으로 동작합니다. 하지만 애플리케이션에 특화된 레코드 단위 파일 시스템은 현재 제공되고 있지 않습니다.
너무 특정 애플리케이션에 특화되어 OS의 generality를 상당히 낮출 수 있기 때문입니다.
'CS > Operating System' 카테고리의 다른 글
| 28. Free Block Management (0) | 2024.02.04 |
|---|---|
| 27. File Structures (0) | 2024.02.04 |
| 25. Files and Directories (0) | 2024.02.03 |
| 24. Device Drivers (2) | 2024.01.31 |
| 23. I/O Device 관리 (1) | 2024.01.30 |