이번에 스터디에서 발표된 논문은 AdderNetwork입니다. 이 논문을 읽으면서 의문점이 많이 들어서 따로 자료들을 더 찾아봐야겠습니다.
Conv Layer에서 기존에 사용하는 multiplications 연산은 상당한 량의 GPU 메모리와 전력을 소비합니다. 이 때문에 다른 휴대용 기기에 사용하기가 어려워 MobileNet과 같이 경량화된 모델이 제안됐지만 여전히 많은 연산량이 필요합니다. 본 논문에서는 Adder을 활용하여 연산량을 줄이는 방법을 사용합니다. 기존에는 BNN 등 다양한 이진화 과정을 거쳐 경량화했지만 이 방법은 학습 속도 저하와 성능 손실이 발생하는 문제들이 있었습니다.
제시된 방법은 다음과 같습니다.
1. Convolution 연산은 filter와 입력의 유사도를 측정하는 방법으로 생각하여 기존 연산보다 더 경량화된 L1-distance를 사용 (곱셈 방식을 덧셈 방식으로 대체한다.)
2. L1-distance에 맞는 back-propagation을 적용하여 기존 BNN이 가진 불안정한 학습을 해결
3. FPG 문제점은 Adative learning rate를 사용하여 해결한다.

Adder Networks


Convolution 연산 결과는 양수, 음수가 나올 수 있지만 L1-distance는 항상 음수만 나오기 때문에 AdderNet 이후에 batch norm을 적용하고, CNN의 activation function을 사용합니다. 두 번째 사진을 통해 AdderNet과 CNN의 차이를 알 수 있습니다. CNN의 경우 input과 filter 간의 cross correlation을 계산하는데, 그 값들이 정규화되면 conv 연산은 두 벡터 간의 cosine distance를 계산하는 것과 같아 각 class의 feature를 각도에 따라 분류를 할 수 있습니다. AdderNet의 경우는 L1-distance를 사용하기 때문에 서로 다른 중점을 기준으로 feature가 군집화 됩니다.
- 입력이 양수여도 음수로 바뀌니 데이터 분포가 변하기 때문에 batch norm을 사용하는 건가?
- cross correlation = 내적, cosine distance = 코사인 유사도
- distance라는 것이 현실적으로 정확한 예측을 하기 어렵다고 했는데 괜찮은 방법인가?
- 연산량 비교 (input: $X \in \mathbb{R}^{H \times W \times c_{in} }$, filter: $F\in \mathbb{R}^{d\times d \times c_{in} \times c_{out}}$, output: $Y\in \mathbb{R}^{H'\times W' \times c_{out}}$)
→ Convolution + batch norm : $\mathcal{O}(d^2c_{in}c_{out}HW)$+$\mathcal{O}(c_{out}H'W')$
→ $l_1$distance + batch norm: ?? + $\mathcal{O}(c_{out}H'W')$
→ batch norm도 곱셈 연산이 포함되어 있지만 conv. 대비 매우 낮은 수준입니다.
Optimization
SGD를 사용하여 parameter update를 합니다. CNN에서 filter F에 대한 output Y의 편미분 값은 다음과 같습니다.
- $\frac{\partial Y(m,n,t)}{\partial F(i,j,k,t)}=X(m+i,n+j,k)$
- 여기서 $i \in [m,m+d] and j \in[n,n+d]$입니다.
이와 다르게 AdderNet에서는 filter F에 대한 output Y의 편미분은 다음과 같습니다.
- $\frac{\partial Y(m,n,t)}{\partial F(i,j,k,t)}=\text{sgn}(X(m+i,n+j,k)-F(i,j,k,t))$
여기서 sgn($\cdot$)은 sign 함수로, gradient는 -1, 0, 1값만을 가질 수 있으므로, signSGD를 적용하여 최적화를 수행해야 합니다. 하지만, signSGD는 SGD처럼 방향을 가지지 않으므로, 다수의 parameter를 update하는 neural network에서 학습을 불안정하게 만듭니다.
- 연산량을 줄이기 위해 sign을 사용하는 건가?
- 방향을 가지지 않는다는 것은 무슨 의미일까? = signSGD는 가장 가파른 기울기를 가지는 하강 방향을 취하지 않으면 차원이 커질수록 대부분 성능이 떨어지는 모습을 보였다.
이러한 문제점을 해결하기 위해서 AdderNet에서는 L2-norm의 편미분 값을 SGD update에 적용하여 full-precision gradient를 사용합니다.
- $\frac{\partial Y(m,n,t)}{\partial F(i,j,k,t)}=X(m+i,n+j,k)-F(i,j,k,t)$
- sign가 BNN과 비슷하게 만들어주는 것 때문에 불안정해진다?
- full-precision gradient란? 자료 형태?
이 수식이 논문에서 주장하는 핵심 내용으로, 업데이트된 l2-norm의 기울기입니다. 필터의 기울기도 중요하지만 그 외에도 입력 피쳐인 X도 학습에 있어 중요한 부분 중 하나입니다. chain rule로 학습이 진행되니 이전 레이어에도 영향을 미칩니다. 위와 같은 식으로 back propagation을 진행하니 기울기 값 범위가 -1, 1 값을 넘어가기에 기울기 폭발(gradient exploding) 현상이 발생할 수 있습니다. 이를 방지하기 위해 Hard Tanh 함수를 사용합니다.
- $\frac{\partial Y(m,n,t)}{\partial X(m+i,n+j,k)}=\text{HT}(F(i,j,k,t)-X(m+i,n+j,k))$
- $\text{HT}(x)= \begin{cases} x &\text{if } &-1<x<1&, \\ 1 &&x>1, \\ -1 &&x<-1. \end{cases}$
- 기울기 값이 일정 범위를 넘어가면 제한을 가해 문제를 해결
Adaptive Learning Rate Scaling
- $Var[Y_{\text{CNN}}]=\sum_{i=0}^{d}\sum_{j=0}^{d}\sum_{k=0}^{c_{in}}Var[X \times F]=d^2c_{in}Var[X]Var[F]$
기존 CNN의 가중치와 입력 피쳐가 독립적이고 정규 분포에 따라 동일하게 분포한다고 가정하면 출력의 분산은 위와 같습니다.
- 만약 weight의 variance가 $Var[F]=\frac{1}{d^2{C_{in}}}$이 되면 output의 variance가 input의 variance와 항상 동일해집니다. 이 경우 neural network의 information flow에 도움을 줍니다.
- 반면 AdderNet의 경우 F와 X가 normal distribution을 따를 때, output의 variance는 다음과 같이 근사화 가능합니다.
$\begin{aligned}Var[Y_{\text{AdderNet}}]&=\sum_{i=0}^{d}\sum_{j=0}^{d}\sum_{k=0}^{c_{in}}Var[|X -F|]\\&=\sqrt{\frac{\pi}{2}}d^2c_{in}(Var[X]+Var[F])\end{aligned}$
- CNN의 $Var[F]$는 일반적으로 $10^{-3}$ 또는 $10^{-4}$와 같이 매우 작은 값을 가지는데 이 때문에 소수의 곱셈을 진행하는 CNN에서의 가중치의 variance가 작아집니다. 그러나 AdderNet의 경우 두 variance의 덧셈으로 표현되므로, output의 variance는 CNN의 output보다 커집니다.
- AdderNets이 큰 분산을 가질 때, activation function의 효율을 높이기 위해서 덧셈 계층 이후에 batch normalization을 진행합니다. batch normalization layer은 아래와 같이 표현됩니다.
$y=\gamma\frac{x-\mu_{B}}{\sigma_{B}}+\beta$
- $mini-batch B={x_1, x_2, x_3, ..., x_m}$ 에서 $input x$가 줄어졌을 때
여기서 \gamma와 \beta는 학습을 통해 구해지는 parameter이고, mini-batch의 mean과 variance가 \mu_S=\frac{1}{m}\sum_{i}, \sigma_{\mathcal{B}}^2=\frac{1}{m}\sum_{i}(x_i,\mu_{\mathcal{B}})^2입니다.
$x$의 Loss $l$의 gradient는 다음과 같이 계산합니다.
- $\begin{aligned} \frac{\partial \mathcal{l}}{\partial x_i}&=\sum_{j=1}^{m}\frac{\gamma}{m^{2}\sigma_{B}} \biggl\{ \frac{\partial l}{\partial y_i}-\frac{\partial l}{\partial y_j}\biggl[ 1+\frac{(x_i+x_j)(x_i+\mu_{B})}{\sigma_{B}}\biggl]\biggl\} \end{aligned}$
- AdderNet output variance에서 output variance $Var[Y]=\sigma_{\mathcal{B}}$가 더 커진다면 loss의 gradient가 감소하게 되고, 이는 학습 속도 저하를 유발합니다.
- distance로 특징을 뽑아낼 경우 현실적으로 정확한 예측을 하기 어렵다고 들었는데 (변형된 이미지에 대해서 같은 distance를 반환해줌) 여전히 문제가 있는 건지 아니면 그러한 문제를 해결한 건지 조금 더 알아봐야겠습니다.

Table 1. 은 LeNet-5-BN 모델에 CNN과 AdderNet을 각각 적용하고, MNIST dataset으로 1회 iteration을 수행했을 때, filter의 gradient에 대한 \mathcal{l}_2norm의 값을 나타냅니다. 각 layer에서 AdderNet이 CNN 대비 낮은 gradient를 가짐을 알 수 있습니다. Learning rate를 늘리는 선택을 할 수 있지만, 표의 실험 결과에서 볼 수 있듯이 gradient의 norm이 layer 별로 다르기 때문에 효과를 장담할 수 없습니다. 그렇기 때문에 본 논문에서는 Adative learning rate를 제안합니다.
$\Delta F_l=\gamma \times \alpha_l \times \Delta L(F_l)$
$\gamma$는 해당 layer에만 적용되는 Local learning rate이고 $\delta L (F_l)$은 layer filter의 gradient이고 $\alpha_l$은 Local learning rate입니다. AdderNets에서 filter는 input의 distance를 계산해서 input에서 특징을 뽑아내는데 더 적합합니다. batch normalization으로 인해 layer들끼리 정규화가 이루어져서 Local learning rate는 다음과 같습니다.
- Local learning rate는 해당 layer에서만 적용됩니다.
$\alpha_l=\frac{n\sqrt{k}}{||\Delta L(F_l)||_2}$
$k$는 F의 원소 수이며, $\eta$는 adder filter의 learning rate를 control 하기 위한 hyper-parameter입니다. 제안된 adaptive learning rate scaling을 사용하면, 서로 다른 adder filter가 거의 동일한 step에서 update 될 수 있습니다.
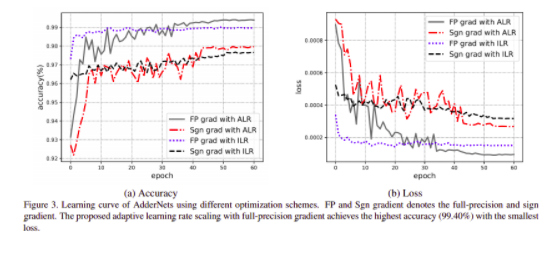
Result
'논문 리뷰 > 경량화 논문 스터디' 카테고리의 다른 글
| [논문 리뷰] Distilling the Knowledge in a Neural Network (NIPS 2014 Workshop) (0) | 2021.10.26 |
|---|---|
| [논문 리뷰] GhostNet: More Features from Cheap Operations, CVPR 2020 (0) | 2021.10.06 |
| [논문 리뷰] 경량화 기술 동향 (0) | 2021.09.21 |
| [논문 리뷰]Rethinking the Value of Network Pruning, ICLR 2019 (0) | 2021.09.06 |
| [논문 리뷰]EfficientNetV2: Smaller Models and Faster Training (0) | 2021.08.29 |