https://www.youtube.com/watch?v=QZekRr4xUAk&t=1s
논문을 읽다 보면 항상 제안된 방법들이 뛰어난 성능을 보인다는 내용들이 많았지만 실제로 문제에 적용하기 전까지는 제대로 된 성능이 나오는지 확인할 수 있는 방법이 없습니다. 이 영상에서는 직접 YOLOv5x 모델을 여러 경량화 기법들을 적용해서 좋은 성능을 보여준 방법들이 정리되어있습니다.
영상에서는 드론에 들어있는 디바이스에서 YOLOv5x 를 돌리는 것을 목표로 내용이 진행됩니다.
경량화를 진행한 경우
다음과 같은 이점들이 존재합니다. 전체적으로 비용이 감소하며, 성능이 증가합니다. 그러면 무조건 경량화 기법을 쓰면 성능이 증가하면 비용이 감소할까요?
우선 일부 경량화 방법은 하드웨어와 밀접한 관계를 가지고 있기 때문에 원하는 디바이스에서 실용적인지 확인이 필요합니다. 모델을 돌리는 디바이스에서 pruning과 quantization이 지원되는지를 잘 확인해야 합니다.
디바이스에 따라서 quantization이 진행된 것들이 CPU, GPU에서 다시 float32, int16 변경한 다음 연산이 진행되어 오히려 성능이 늘어지는 경우도 있습니다.
The Lottery Ticket 논문에서는 pruning이 다수의 weight들을 제거해도 이전과 비슷한 성능이 나왔습니다. 그래서 성능을 유지하는 선에서 pruning을 진행한다면 0이 된 부분을 무시하고 진행해서 속도가 더 빨라지고 용량도 더 줄어들어가고 예상을 했었습니다. 하지만 실제로는 그냥 0이 많은 모델이었고 속도와 용량도 그대로였습니다.
그럼 pruning은 경량화에 도움을 주지 못하는 방법일까요? 0이 많은 모델은 압축으로 사이즈를 줄이기 용이합니다. 그래서 네트워크로 전송할 때 트래픽에 이점이 생깁니다.
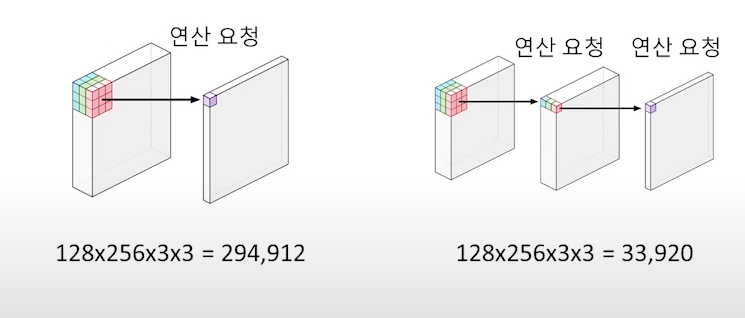
경량화 기법 중에서 mobilenet에서 사용한 방법인 depthwise separable convolution이 존재합니다. 이론적으로는 이 방법은 항상 빠르다고 하지만 실제로는 하드웨어가 한 번에 연산할 수 있는 양에 따라 달라집니다. 이미 레이어가 많이 작다면 일반적인 convolution이 더 빠를 수도 있습니다.
현재 이미지 처리에서 CNN이 아닌 Transformer를 많이 사용하는데 실제 적용에서는 하드웨어나 소프트웨어 둘 다 CNN 연산에 맞는 최적화가 더 많이 진행되어있어서 성능은 경량화 모델로서 잘 나오지만 속도적인 면에서는 아직 CNN이 더 빠릅니다.
밑바닥부터 만들지 않는 이상 우리의 하드웨어에 적합한 경량화를 적용하기는 힘듭니다. 그래서 소프트웨어 부분으로 경량화를 진행하는데 그 방법들은 다음과 같습니다.
1. 새로운 아키텍처를 만드는 방법
- task 도메인을 잘 알아서 그 도메인에 최적화된 모델을 만들어야 함
2. 이미 만들어진 아키텍처를 압축 (pruning, quantization, tensor decomposition)
- 이미 만들어진 모델을 압축하는 것이니 도메인을 잘 몰라도 됨

새로운 딥러닝 블록을 만드는 것은 쉬운일이 아닙니다. 그래서 다음과 같이 이미 공개되있는 블럭 중 우리의 task에 최적화된 블럭을 자동으로 찾는 방법이 있습니다. (AutoML)
- OPTUNA는 hyperparameter search에서 굉장히 유용하고 Weights & Biases는 모델의 성능을 판단해줍니다.

OPTUNA로 모델을 자동 생성하고 평가를 진행하면서 진행이 되는데 이 시간이 오래 걸리기 때문에 모든 데이터를 사용하는 것이 아니라 줄여서 사용해야 합니다. (우리의 task에 최적화된 블록은 조금만 학습시켜도 좋은 평가지표가 나옴)
또는 search space를 줄이는 것도 좋은 방법입니다. 아니면 하이퍼 파라미터와 모델 두 개를 동시에 찾는 것이 아니라 우선 모델을 찾고 나중에 하이퍼 파라미터를 찾는 방식으로 진행하는 것도 하나의 방법입니다.
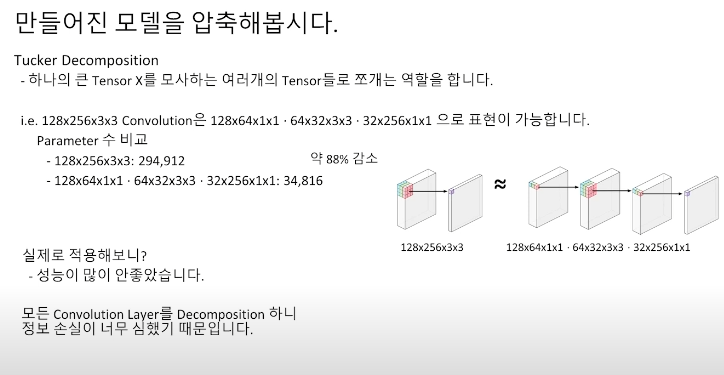
이 영상에서는 모델을 압축할 대 tensor decompostion 중에서 tucker decompoistion에 중점을 두고 진행했습니다.
하나의 큰 텐서를 작은 텐서 여러 개로 분해합니다. 모든 레이어에 적용했을 때 큰 파라미터 감소량을 보였지만 성능이 좋지 않았습니다. (convolution layer를 분해하니 정보 손실이 커짐)
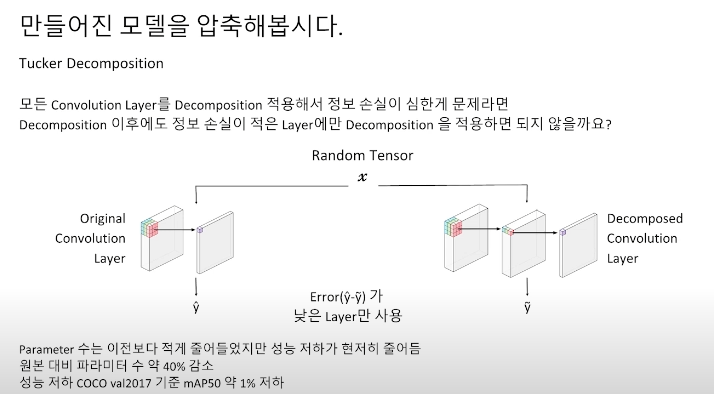
그래서 모든 convolution layer를 decompostion 하는 것이 아니라 정보 손실이 적었던 layer에 대해서만 decompostion을 진행했습니다.
- 정보 손실의 정도를 어떻게 측정해야 하나?
원본과 분해된 convolution layer에다 random tensor 연산을 돌려서 error가 낮은 layer에만 적용하면 됩니다. 분해는 결국 convolution layer의 가중치 중 큰 텐서들을 작은 텐서로 모사하는 과정이기 때문에 가중치 내부에 0이 많으면 더 작은 텐서로 decompostion 할 수 있습니다. (sparse 한 matrix의 경우 모델 압축하는데 용이하다.)
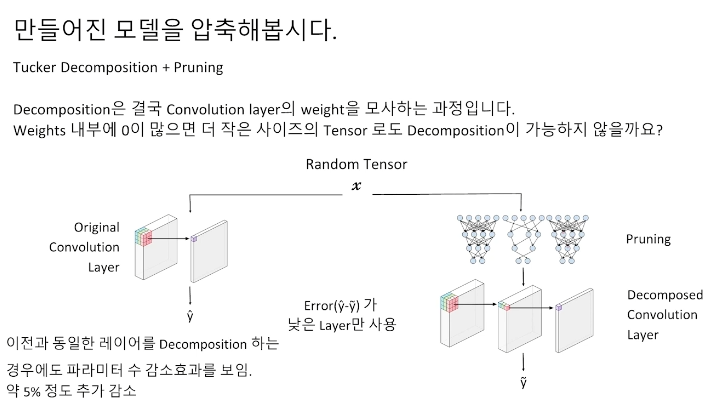
그래서 다음과 같이 pruning과 tucker decompostion을 같이 사용하여 파라미터 수를 더 감소시킬 수 있었습니다. 그런데 파라미터 수 감소 효과는 대부분 pruning의 강도에 비례했는데 레이어 별로 많이 해도 되는 레이어가 있고 그렇지 않은 레이어가 존재하기 때문에 이점을 생각하여 pruning ratio를 적절히 조절하기 위해 binary search를 이용해서 결정했습니다. (파라미터 수가 2% 더 감소가 됨)
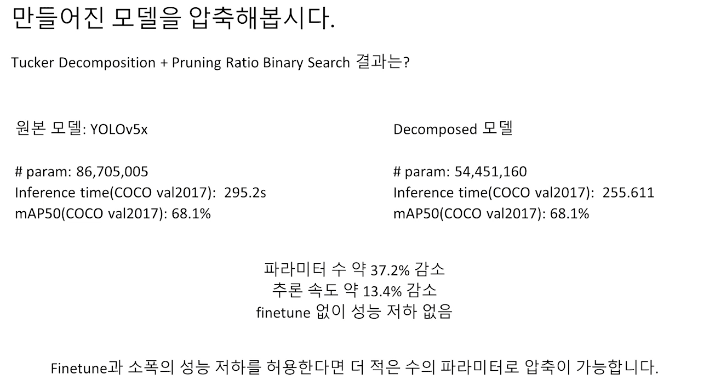
다음과 같은 결과물이 나왔습니다.
추가적으로 더 경량화를 진행한다면
1. GPU가 FP16을 지원한다면 half percision만 사용해도 속도 향상을 얻을 수 있습니다.
2. 가장 많이 병목이 생기는 GPU - CPU 사이의 메모리 이동 부분을 어떻게 병렬화 할지 고려해야 합니다. (아니면 데이터 이동 자제)
3. Tensor RT를 사용하는 것도 좋은 방법입니다.
4. 모델 경량화도 중요하지만 코드 최적화도 중요합니다.
- 입력 이미지를 어디서 디코딩할 건지, 전처리를 어디서 할 건지(CPU, GPU), 모델 추론할 때 멀티코어 활용하기
'Pseudo Lab > 4기 Mobile AI crew' 카테고리의 다른 글
| [논문 리뷰] Knowledge distillation: A good teacher is patient and consistent (0) | 2022.05.10 |
|---|