
synchronization에 대해서 이야기하려면 2개 이상의 프로세스가 필요합니다. synchronization 문제는 논리적 연관성이 있는 프로세스들에서도 일어날 수 있지만 아무런 logical 한 연관성이 없는 프로세스라고 하더라도 서로 컴퓨터 시스템 내에서 자원을 공유하기 때문에 synchronization로 인한 문제가 발생할 수 있습니다.

synchronization 문제는 data sharing이나 resource sharing으로부터 발생합니다. 이러한 문제는 오퍼레이션이 진행 중 interrupt service routine이 일어나 값을 바꾸는 상황에서 발생합니다. 그래서 오퍼레이션이 interrupt service routine에 방해를 받지 않는 상태를 만들어야 합니다. 이런 영향을 받지 않는 오퍼레이션을 atomic operation이라고 합니다. (하드웨어적으로 interrupt를 masking 하는 방법이 존재합니다, 이를 통해 interrupt가 발생하여 값이 변경되는 상황을 막을 수 있습니다.)

프로세스들 사이에서 synchronization 문제가 발생할 수도 있지만 프로세스와 interrupt service routine과도 synchronization 문제를 발생시킬 수 있습니다. 혼자서 진행했을 때는 문제가 없지만 두 개 이상의 개체가 영향을 미칠 경우 문제가 발생하는 코드를 non reentrant라고 부릅니다. 이런 non reentrant 코드에 disable interrupt와 enable interrupt를 추가하여 다른 개체의 영향을 무시하게 되면 reentrant 코드가 됩니다. (share data에 access 하는 전체 연산을 atomic 하게 만들 경우)
이런 atomic한 연산을 하기 위해서는 OS preemptive들 중 synchronization preemptive가 필요합니다.
ex)

다음과 같이 share data structure인 buffer를 공유하는 코드가 있습니다. 이 버퍼를 임의로 다른 프로세스가 사용하는 것을 허용하면 synchronization 문제가 발생하게 되니 해결 방법을 찾아야 합니다. flag 변수를 통해 다른 프로세스가 사용할 경우 False, 사용하지 않을 경우를 True로 설정하여 변수에 접근할 수 있는지 없는지를 확인할 수 있습니다.

프로세스 1, 2가 존재하며 두 프로세스 모두 버퍼를 사용하고 싶어 할 때 flag를 적용해 보겠습니다. 프로세스 1이 버퍼에 접근하고 flag를 False로 설정하기 전에 프로세스 2로 context switching이 일어나면 프로세스 2는 flag를 True로 생각하여 버퍼를 사용하는 판단을 하게 됩니다. 즉 두 프로세스가 버퍼를 사용하는 문제가 발생합니다. (프로세스 1에서 flag를 flase로 만들고 버퍼에 접근하는 연산이 쪼갤 수 있기 때문에 일어나는 일, atomicity가 지켜지지 않음)
share data로 인한 문제를 해결하기 위해서 flag 변수를 도입했는데 프로세스들의 입장에서 보면 flag 변수도 일종의 share data 이기에 이런 문제가 발생하는 것입니다. 이 flag 변수를 atomic하게 쓰기 위해서 또 다른 synchronization preemptive가 필요해지기 때문에 제대로 된 제어를 하지 못합니다.

flag를 읽어서 수정하는 이 과정이 하나의 atomic operation이 되어야 되기 때문에 OS에게 이 부분을 알려줘서 atomicity가 보장되도록 해줘야 합니다. atomic하게 수행되는 부분에서는 mutual exclution이 발생했다고 하는데 이 의미는 atomic operation에서 하나의 프로세스만 동작할 수 있다는 것을 의미합니다. 줄여서 mutex라고 부릅니다.
mutex가 발생하는 코드의 한 부분, code segment를 critical section이라고 부르며 사용자 코드에서 존재하는 모든 critical section 안에서는 mutex가 보장되어야 합니다.
Semaphore

semaphore는 프로세스가 공유자원을 사용할 때 생기는 문제를 해결하기 위해서 OS가 제공하는 Synchronization mechanism입니다. 세마포어를 액세스할 수 있는 함수 P와 V가 존재하며 P는 접근 권한을 달라는 요청이고 V는 접근 권한을 주는 오퍼레이션입니다.
P 오퍼레이션은 2가지 동작을 가지고 있습니다. 요청을 보냈을 때 다른 프로세스가 공유 리소스를 사용하는 중이라 접근을 실패했다면 wait queue에서 대기를 하게 되고 접근에 성공한다면 Lock을 걸어 다른 프로세스가 접근하지 못하도록 합니다. V 오퍼레이션은 P 오퍼레이션 다음에 진행되는 동작으로 Unlock을 진행합니다.
code segment에서 P 오퍼레이션으로 시작되어 V 오퍼레이션으로 끝나는 부분을 critical section이라고 부르며 critical section안에서는 mutex가 보장되어야 합니다. mutex를 보장해 주는 세마포어는 Synchronization mechanism 문제를 해결해 주는 integer 변수입니다. (접근 권한이 프로세스에게 있으면 0, OS에게 있으면 1로 OS가 권한을 가지고 있을 때 다른 프로세스들이 접근할 수 있습니다.)
ex)

위 사진은 두 프로세스가 critical section에 접근하는 모습을 보여줍니다. critical section에 접근하기 직전에 해야 하는 동작이 P(S1)이고 critical section을 벗어나면서 해야하는 동작은 V(S1)입니다. P, V 오퍼레이션은 반드시 파라미터로서 세마포어 변수를 받아야 하는 것을 알 수 있습니다. (세마포어의 값은 사용가능한 리소스의 개수로 초기화 되어야 합니다.)

세마포어로 공유 리소스를 표현하는 방법에는 2가지가 존재합니다. 자원이 있는지 없는지를 0, 1로 표현하는 binary semaphore와 사용가능한 리소스 개수가 1개보다 많아져서 접근 권한을 여러 개로 늘리는 경우인 counting semaphore, 이렇게 2가지 방법으로 사용됩니다.
세마포어가 mutual exclution을 제공해 주는 것에 대해 알아봤는데 세마포어는 스케줄링도 제공해 줍니다. 한 프로세스가 critical section에 들어가 있는 경우 다른 프로세스들의 접근을 막고 waiting queue에 대기를 시키는데 이 동작을 일종의 스케줄링으로 볼 수 있기 때문입니다.
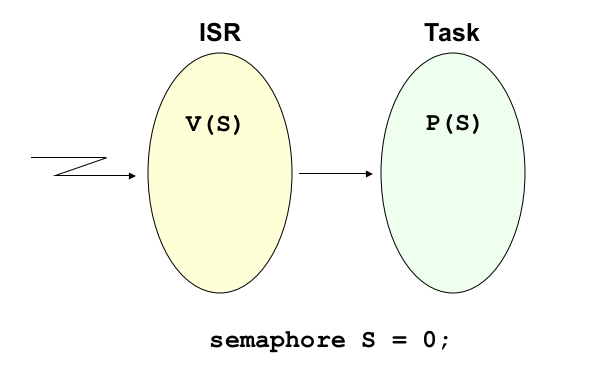
이번에는 세마포어를 스케줄링을 위해서 사용하는 방법에 대해서 알아보겠습니다. 프로세스들은 웨이팅에 빠져있다가 기다리던 이벤트가 발생하면 다시 ready queue로 들어갑니다. 이벤트는 대부분 인터럽트의 형태로 인터럽트가 그 인터럽트를 기다리는 task를 깨워주게 됩니다. (인터럽트로 세마포어를 제어)
실행 중이던 프로세스를 waiting queue로 이동시키는 과정과 waiting queue에서 대기하던 프로세스를 인터럽트로 깨워주는 과정을 P, V 오퍼레이션을 사용하여 수행할 수 있습니다. waiting의 경우 프로세스에서 P 오퍼레이션을 실행하고 인터럽트 서비스 루틴에서 V 오퍼레이션을 실행하여 다시 ready queue로 프로세스를 이동시킵니다.
세마포어의 값은 0으로 초기화시켜야 합니다. P 오퍼레이션을 실행시켰을 때 waiting queue로 돌아가는 동작을 해야 되기 때문입니다. (interrupt service routine이 V 오퍼레이션으로 깨워주기 전까지 대기해야 해서)

이번에는 세마포어를 다른 방식으로 사용해 보겠습니다. 프로세스에는 데이터를 생성하는 producer process와 생성된 데이터를 소모하는 consumer process가 존재합니다. 생성된 데이터를 사용하기 위해서는 버퍼(buffer)라는 shared memory가 필요합니다. (인터럽트 대신에 두 프로세스가 세마포어를 제어)

사진은 producer/consumer model with bounded buffer를 그림으로 표현하고 있습니다. buffer를 통해서 서로 정보를 공유하는데 사진에서는 버퍼 사이즈가 3입니다. producer-consumer 모델에서는 바운디드 버퍼(bounded buffer)를 사용합니다. 바운디드 버퍼는 저장할 수 있는 아이템의 개수가 제한된 버퍼로 생각하시면 됩니다.
producer process의 동작에 대해 알아보겠습니다. producer process는 먼저 버퍼에 빈 공간이 있는지 확인을 합니다. 공간이 없다면 waiting을 하고 공간이 있다면 바로 데이터를 넣는 동작을 진행합니다. consumer process의 경우 반대로 버퍼가 비워져 있다면 waiting 하고 버퍼가 채워져 있다면 데이터를 읽는 동작을 진행합니다.
이 구조를 구현하기는 상당히 어렵습니다. shared memory 접근에 대한 세마포어가 필요하고 버퍼의 상태에 따라서 producer, consumer 동작을 진행해야 합니다.

프로세스 간의 synchronization 문제를 해결하기 위해서 제일 먼저 해야 하는 일은 어떤 세마포어를 사용할지 pool list를 만드는 것입니다. 먼저 어떤 리소스들이 shared resource이고 guard resource인지 알아야 합니다. 우선 버퍼를 shared memory로 설정해서 동작을 알아보겠습니다.

shared resource인 버퍼는 액세스 하는 시작 부분과 끝부분이 critical section 이기 때문에 P, V 오퍼레이션으로 보호가 되어야 합니다. 여기서 버퍼만 shared resource로 생각해 세마포어가 버퍼만 보호한다면 문제가 발생합니다. 예시를 들기 위해서 버퍼에 대한 접근 여부를 알려주는 buf_avail이라는 flag는 1로 초기화를 진행해 보겠습니다.
이때 buf_avail이라는 flag만 존재한다면 consumer의 동작을 제어할 수 없습니다. buf_avail이 1로 초기화된 상태에서 producer가 데이터를 넣기 전에 consumer가 access한다면, 공유 리소스 접근에 성공하지만 데이터가 없어서 읽는 동작을 하지 못하는 상황이 벌어집니다. (consumer 접근을 제한하는 flag가 없음)
이런 문제가 발생하는 이유는 shared resource가 버퍼만 존재하는 것이 아니기 때문입니다. consumer 입장에서는 버퍼가 공유 리소스가 아니라 버퍼 안에 있는 데이터가 공유 리소스입니다. 그래서 버퍼 안에 데이터가 있는지 여부를 알려주는 flag가 따로 필요합니다. 초기화는 버퍼는 빈 상태 1, 버퍼가 비워진 상태로 데이터가 없으니 0으로 초기화합니다.
P 오퍼레이션은 리소스를 소모하는 오퍼레이션으로 producer process에서는 버퍼를 소모해서 buffer flag를 0으로, consumer process에서는 데이터를 소모해서 data flag를 0으로 만듭니다. V 오퍼레이션은 생성하는 오퍼레이션으로 producer process에서는 데이터를 생성하고, consumer process에서는 버퍼를 생성합니다.
이번에는 하드웨어에서 제공하는 disable/enable interrupt와 P, V operation을 비교해 보겠습니다.
interrupt를 disable 한다는 것은 system wide 하게 모든 프로세스가 서로 다른 공유 리소스에 접근하지 못하게 되는 것을 의미합니다. 세마포어의 경우 다른 공유 리소스에서 다른 세마포어 변수를 사용하여 각각 독립적으로 접근할 수 있지만 disable/enable을 사용할 시 독립적으로 사용될 수 있는 공유 리소스들에 대한 접근들도 모두 통제당하게 됩니다.
- disable/enable interrupt의 경우 부산에서 신호등에 빨간불이 들어오면 서울에서도 모두 멈춰야 하는 상황 (모든 공유 리소스에 적용된다)
- semaphore의 경우 지역이 다르면 다른 신호등을 사용하여 문제가 발생하지 않음 (일부 공유 리소스에만 적용된다)
disable/enable interrupt는 글로벌하기 때문에 사용하기 전에 조심해야 합니다. 대부분의 경우 세마포어를 사용하여 어느 특정 리소스를 공유하는 프로세스들을 보호합니다.

세마포어는 unstructured construct로 소프트웨어 툴이 찾을 수 없는 오퍼레이션입니다. malloc을 한 뒤 free를 하지 않더라도 소프트웨어 툴이 발견하지 못하는 것과 같은 상황인 것입니다. 반대로 if문 같은 경우 중괄호를 빼먹어서 범위 설정이 제대로 되지 않은 경우 소프트웨어 툴이 발견할 수 있는데 이런 구조를 structed construct라고 부릅니다.
위 사진의 코드처럼 Task2에서 P(S2)로 S2 세마포어 변수의 접근을 차단한 상태에서 실수로 S2가 아닌 S1 접근을 풀어버리더라도 이 부분에서는 오류가 발생하지 않기 때문에 어디서 문제가 발생했는지 찾기가 어려워집니다. 이런 P, V 오퍼레이션의 페어가 제대로 이루어지지 않아서 발생하는 synchronization error를 race condition이라고 부릅니다.
또한 Task1을 스케줄링으로 본다면 맞지만 producer로 본다면 틀리게 됩니다, Task2의 경우 consumer로 본다면 맞는 동작일지 모르지만 스케줄링으로 본다면 틀리게 됩니다. (어떤 것이 틀린지 알 수 없음)

OS에서는 이런 문제를 해결하기 위해서 기존 스케줄링 P, V 오퍼레이션과 producer-consumer의 세마포어 오퍼레이션의 이름에 차이를 두었습니다. P 오퍼레이션을 wait으로 사용한 경우 세마포어를 스케줄링 관점에서 사용한 것이 되고 P 오퍼레이션을 mutex_lock으로 사용한 경우 세마포어를 mutual exclusion 보장하기 위해서 사용한 것이 됩니다.
- 즉 이 문제는 Task1에서 프로듀서가 unlock을 잘못 해준 것으로 볼 수 있습니다.
'CS > Operating System' 카테고리의 다른 글
| 10. 모니터(Monitor) (1) | 2023.12.06 |
|---|---|
| 9. 세마포어(semaphore) (2) | 2023.11.26 |
| 7. 스케줄링(Scheduling) (2) | 2023.10.31 |
| 6. 리소스(Resource) (0) | 2023.10.24 |
| 5. 멀티 쓰레딩(Multi Threading) (2) | 2023.10.17 |