지금까지 OS가 지원해주는 synchronization preeptive들 중 세마포어에 대해서 공부했습니다. 이번에는 OS 내부에서 세마포어를 어떻게 구현하는지에 대해서 알아보겠습니다.

세마포어는 인티저(integer) 변수로 availavle한 리소스 인스턴스의 개수를 표현하는 인티저 값 입니다. 일반적인 경우 0과 1값을 가지지만 리소스 인스턴스가 여러 개가 있는 경우 counting semaphore라고 하여 사용가능한 리소스 인스턴스 개수만큼 값을 설정합니다.
세마포어를 구현할 때 인티저 카운터 변수외에 queue structure가 필요합니다. P 오퍼레이션을 했을 때 세마포어를 획득하기 못했을 때 대기해야 하는 프로세스들에게 사용하기 때문입니다.

P, V 오퍼레이션은 다음과 같이 구현됩니다.
P operation
available resource instance가 1개인 경우
- 리소스가 존재할 때 (카운터 값이 양수인 경우)
- 세마포어가 가지고 있는 카운터 변수가 0보다 큰지 확인합니다. (리소스 확인)
- 리소스가 존재한다면 return을 통해서 리소스를 반환합니다.
- auto decrement 연산을 통해서 카운터 값을 감소시킵니다.
- 리소스가 존재하지 않을 때 (카운터 값이 0이나 음수일 경우)
- 프로세스가 카운터 값을 확인합니다.
- sleep을 하게 됩니다.
- 여기서도 카운터 값을 1빼기 때문에 음수가 되지만 0과 동일하게 생각하시면 됩니다.
- 카운터 값이 음수일 때 이 값에 절대값을 씌우면 현재 큐에서 대기 중인 프로세스의 개수가 나옵니다.
여기서 카운터 변수를 읽는 과정을 atomic하게 만들기 위해서 disable/enable interrupt를 사용했습니다. 이는 세마포어의 구성 요소인 카운터 변수와 waiting 큐 또한 shared resource 이기 때문에 보호하기 위해서 사용한 것입니다.
- 왜 세마포어 대신에 disable/enable interrupt를 사용한 것일까?
- 세마포어를 보호하기 위해서 세마포어를 사용하는 것이 해결책이 되지 않기 때문에
interrupt가 사용된 부분은 메모리에 엑세스해서 확인하고 그 값을 modify하는 짧은 오퍼레이션이기 때문에 disable/enable interrupt를 사용하더라도 성능 저하가 적습니다. (critical section이 작을 때 disable/enable interrupt가 P, V 오퍼레이션 보다 효과적)
context switching이나 scheduling을 유발하는 P, V 오퍼레이션을 사용하는건 오히려 오버헤드가 발생하여 비효울적일 수 있습니다.
V operation
- 세마포어 카운터 값이 0이나 양수일때
- 세마포어의 카운터에 접근하기 이전에 disable interrupt를 진행합니다.
- 카운터 값이 0이나 그 이상인지를 확인합니다. (카운터 값이 음수일때만 대기중인 프로세스가 존재)
- 카운터 값을 1 증가시키고 리턴
- 세마포어 카운터 값이 음수일때 (대기 중인 프로세스가 있는 상황)
- 세마포어의 카운터에 접근하기 이전에 disable interrupt를 진행합니다.
- 카운터 값이 0이나 그 이상인지 확인합니다.
- waiting queue에서 대기하고 있는 프로세스를 깨워주고 카운터 변수를 증가시킨 후 리턴
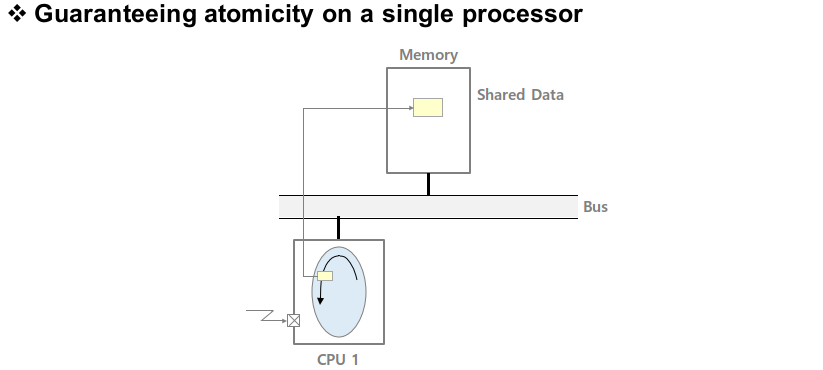
이 P, V 오퍼레이션은 single processor용 오퍼레이션으로 disable interrupt를 발생시켜 다른 프로세스가 스위칭을 통해 CPU를 사용하지 못하게 막습니다. (interrupt가 disable 되어 mode chage가 일어날 수 없기 때문에 context switching이 불가능)

multi processor에서는 위 코드가 제대로 동작할 수 없습니다. 이전과 달리 CPU가 2개가 되어서 두 개의 프로세스를 실행시켜 메인 메모리에 있는 shread data에 access 하고 있다고 해보겠습니다. 이때 CPU1이 interrupt를 disable 시키면 CPU1을 통해서 다른 프로세스가 shared data에 접근하는 것은 막을 수 있지만 CPU2를 통해서 접근하면 막을 수 없기 때문입니다.
- disable interrupt은 disable interrupt를 발생한 CPU가 사용되는 것만 금지시킨다.
그래서 multi processor의 경우 메인 메모리로 연결되는 bus를 막는 방식으로 mutex를 보장합니다. CPU1이 bus를 장악하고 shared data에 access 한다면 다른 프로세서가 메인 메모리에 접근하는 것을 막을 수 있습니다. 이를 통해서 CPU1의 atomicity를 보장해줄 수 있습니다.
read access의 경우 여러 프로세스들이 동시에 진행해도 괜찮지만 write access의 경우 문제가 발생하게 됩니다. 그래서 write access를 하게 될 경우에 bus를 non-preemptive하게 만들어야 합니다. 데이터를 읽어서 수정하는 오퍼레이션의 동작은 bus를 통해 read transaction이 발생한 다음 더 이상 bus와 memory를 사용하지 않고 CPU 연산만을 진행합니다.
CPU 연산이 끝난 후 다시 bus를 잡고 write transaction을 진행하게 되는데 이렇게 되면 read transaction과 write transaction 사이 CPU 연산을 하는 동안 bus를 사용하지 않습니다. 이 구간에 다른 프로세서가 bus를 사용하는 방식으로 bus utilization을 높이는 것이 일반적인 방법입니다.
하지만 read transaction과 write transaction을 나눠서 bus를 계속 독점하지 않게 하는 방법은 atomicity를 제공하는데 문제가 있습니다. 이런 문제점을 해결하기 위해서 bus read modify write transaction을 추가합니다. bus read modify write transaction은 데이터를 read하거나 CPU에서 modify하고 write하는 transaction을 하나로 묶는 방법으로 이 동작들이 끝나야 bus를 다른 프로세서들이 잡을 수 있게 됩니다.
이렇게 하나의 transaction으로 묶으면 multi processor 상황에서도 메모리 오퍼레이션에 대한 atomicity를 보장해줄 수 있습니다. bus read modify write를 하나의 transaction으로 만들 때 test & set instruction을 사용합니다. test & set instruction은 반드시 memory location을 operand로 사용합니다.
test & set instruction은 그 memory location에 있는 값을 read하고 0인지 1인지 test를 합니다. 그 다음 바로 memory location값을 1로 set합니다. 원래 memory location이 0이였다면 1로 변경이 되고 1이였다면 변화가 없게 되는 것입니다. 0을 읽은 프로세서는 리소스를 쓸 수 있고 1를 읽은 프로세서는 리소스를 쓸 수 없습니다. 그래서 0을 읽었을 때 사용해야하니 바로 1로 변경하고 작업을 수행하게 됩니다.
Test & Set Instruction

test & set instruction에 대해서 설명하겠습니다. 위의 빨간 박스가 P 오퍼레이션이고 그 아래 파란 박스가 V 오퍼레이션 입니다. operand로 온 memroy location은 여기서 lockMem이고 TAS(lockMem)은 lockMem의 값을 읽어오는 동작을 합니다. 만약 lockMem이 0이라면 바로 while을 빠져나오고 1이라면 계속 while loop를 돌게 됩니다. (Spin lock)
V 오퍼레이션은 lockMem를 0으로 수정하는 동작을 수행합니다. 이렇게 atomicity를 보장하는 것이 TAS instruction을 이용한 synchronization preemptive입니다. lockMem을 1로 보게 된다면 CPU 사이클을 사용하지 않고 대기하는 것이 아니라 무한히 루프를 돌면서 값을 체크하기 때문에 busy waiting을 하게됩니다.
spin lock만 사용하면 multi processor의 atomicity를 완벽하게 보장해주지 못합니다. spin lock 앞에 disable interrupt를 넣어서 동일한 CPU 일때 다른 프로세스나 인터럽트 서비스 루틴이 atomicity를 깨지 못하게 만들어야 합니다. (spin lock은 다른 프로세서가 방해하지 못하도록, disable interrupt는 같은 CPU 내에서 다른 프로세스가 방해하지 못하도록 합니다.)
세마포어를 사용하게 되면 single / multi processor 두 곳에서 다 스케줄링이 발생할 수 있지만 single processor에서 disable interrupt를, multi processor에서는 disable interrupt와 spin lock을 사용하는 경우 스케줄링이 발생하지 않습니다. 또한 어떤 코드가 인터럽트 컨텍스트를 수행하는 상태라면 인터럽트 서비스 루틴안에 있다는 것이기 때문에 세마포어의 P와 V 오퍼레이션을 쓸 수 없습니다. (인터럽트로 인해서 P, V가 아닌 다른 작업을 진행하게 됨)
세마포어의 P 오퍼레이션은 스케줄링을 발생시키는데 현재 코드를 수행하는 주체가 인터럽트 서비스 루틴이라서 스케줄링의 대상이 될 수 없기 때문입니다. 스케줄링의 대상은 컨텍스트를 제대로 갖추고 있는 프로세스만 가능하기 때문에 인터럽트 서비스 루틴에서는 세마포어를 사용할 수 없습니다. (disable / enable interrupt이나 spin lock 사용이 가능합니다.)
Pthread를 사용한 Mutex
이번에는 POSIX API를 사용하여 세마포어 프로그래밍을 살펴보겠습니다.

다음과 pthread multi hteading을 진행하려면 우선 header file을 참조해야 합니다. 그 다음 mutex라는 세마포어를 하나 선언합니다. pthread_mutex_init을 통해서 세마포어의 data structure를 할당합니다. 그 아래 두 코드 mutex_lock, mutex_unlock은 P와 V에 해당하는 오퍼레이션이고 마지막 mutex_destroy는 세마포어의 자원을 반납하는 일을 합니다.
#include <stdio.h>
#include <string.h>
#include <pthread.h>
#include <stdlib.h>
#include <unistd.h>
pthread_t tid[2];
int counter = 0;
pthread_mutex_t mutex;
본격적으로 프로그래밍에 들어가 보겠습니다. 헤더파일을 include하고 두 개의 쓰레드와 mutex라는 세마포어를 생성합니다.
void *ThreadCode(void *argument)
{
pthread_mutex_lock(&mutex);
unsigned long i = 0;
counter++;
printf(“\n Job %d started.\n”, counter);
for(i=0; i<0xFFFFFFFF; i++);
printf(“\n Job %d finished.\n”, counter);
pthread_mutex_unlock(&mutex);
return NULL;
}
이 코드 쓰레드가 실행하는 코드로 수행을 시작하면 바로 mutex_lock을 하게 됩니다. 끝날 때는 다시 mutex_unlock을 통해서 다른 쓰레드가 critical section에 접근할 수 있도록 해줍니다. critical section에서는 단순히 counter variable이라는 global sahred variable의 값을 1 증가시킵니다.
int main(void)
{
int i = 0, err;
/* Since mutex is a binary semaphore, it gets 1 */
if (pthread_mutex_init(&mutex, NULL) != 0){
printf("\n mutex_init failed.\n");
return 1;
}
while (i < 2){
err = pthread_create(&(tid[i]), NULL, ThreadCode, NULL);
if (err != 0)
printf("\ncan't create thread: [%s].\n", strerror(err));
i++;
}
pthread_join(tid[0], NULL);
pthread_join(tid[1], NULL);
pthread_mutex_destroy(&mutex);
return 0;
}
메인 함수의 동작에 대해서 알아보겠습니다. pthread_mutex_init을 통해서 세마포어를 1로 초기화시킵니다. 그 다음에 pthread_create를 통해서 2번 loop를 돌아 쓰레드를 생성합니다. 메인 쓰레드는 두 개의 쓰레드가 종료될 때까지 기달려야 하기 때문에 pthread_join을 2번 하게 됩니다. 이후 pthread_mutex_destroy를 통해서 메모리를 반환합니다.

이번에는 스케줄링 형태의 세마포어를 사용할 때 필요한 POSIX API들에 대해서 알아보겠습니다. sem_wait은 P 오퍼레이션이고 sem_post가 V 오퍼레이션 입니다. (signal이라는 이름 대신에 비슷한 post를 사용함), 여기서는 sem_wait, sem_post를 사용할 때 mutex 데이터 타입이 아닌 sem_t 타입을 이용해서 세마포어를 할당 받아야 합니다.
#include <stdio.h>
#include <string.h>
#include <pthread.h>
#include <semaphore.h>
#include <stdlib.h>
#include <unistd.h>
pthread_t tid[2];
int counter = 0;
sem_t sem;
헤더파일은 이전 mutex 형태에 semaphore.h 헤더파일이 추가됩니다. 앞에 코드에서 mutex_lock, mutex_unlock을 사용한 부분을 sem_wait, sem_post로 바꿔주면 됩니다.
void *ThreadCode(void *argument)
{
sem_wait(&sem);
unsigned long i = 0;
counter++;
printf(“\n Job %d started.\n”, counter);
for(i=0; i<0xFFFFFFFF; i++);
printf(“\n Job %d finished.\n”, counter);
sem_post(&sem);
return NULL;
}
여기서 wait과 post 함수가 사용되기는 했지만 스케줄링을 위해서가 아닌 critical section을 구성하기 위해서 사용된 것 입니다. 세마포어를 스케줄링으로 사용할 때와 세마포어를 critical section으로 사용할 때를 구분함으로써 race condition이 유발되지 않게 해줍니다.
critical section안에서 blocking system call을 사용하지 않는 것이 좋습니다. critical section에서 동작하는 동안 다른 프로세스들은 waiting하게 되므로 critical section에 들어갔다는 사실만으로 다른 프로세스를 방해하는 것이 됩니다. 이때 blocking을 해버리면 다른 프로세스에 안 좋은 영향을 주게됩니다.
하지만 critical section에서 어떤 이벤트를 기달려야 하기 때문에 대기하는 경우가 생길 수 있습니다. 이때 이벤트를 만들어주기 위해서 다른 프로세스가 동작하게 되면 synchronization이 깨지는 문제가 생깁니다. 이럴 때는 critical section안에 있는 프로세스가 나오고 대기를 합니다.
그러면 다른 프로세스가 critical section에 들어와서 이벤트를 만들어주고 critical section을 나오면서 대기하고 있던 프로세스를 깨워주는 동작을 하게 되는데 이런 메커니즘을 제공해주는 것이 condition variable입니다. (blocking을 하는 대신에 cirtical section을 벗어나서 대기하는 방식으로 해결)

condition variable은 변수가 아닌 일종의 waiting queue입니다. critical section에서 어떠한 자원이 부족하거나 이벤트가 없어서 blocking을 하는 대신에 나와서 대기하는 프로세스가 들어가는 waiting queue라고 생각하면 됩니다. condition variable에는 대기하는 wait과 깨어나서 복귀하는 signal 이렇게 두 가지 오퍼레이션이 있습니다.

condition variable을 코드상에서 사용할려면 POSIX를 이용해야 합니다. condition variable은 pthread_cond_t 를 통해서 선언하면 됩니다. pthread_cond_wait은 condition variable queue에 들어가서 대기하는 함수이고 condition_cond_signal 함수는 대기하는 프로세스를 깨워주는 동작을 합니다.
#include <stdio.h>
#include <pthread.h>
/* static initializers */
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
int data_produced = 0;
int count = 0;
이를 이용해서 producer-consumer를 구현해 보겠습니다. producer-consumer를 세마포어로 구현할 때 두 개의 세마포어를 사용하여 구현했습니다. 이때 생긴 형태는 기존 critical section과 비슷했지만 P와 V에 사용되는 세마포어 변수를 교차하여 사용했습니다.
이번에는 조금 더 쉽게 동일한 세마포어를 사용해서 교차되지 않게 critical section을 구현을 하고 버퍼가 비었을 때나 꽉 찼을 때를 대비한 flow control을 위해서 condition variable을 적용하겠습니다. 위 코드에서 mutex라는 세마포어를 사용했고 condition variable인 cond를 선언합니다.
그 다음에 데이터 있는지 없는지 표현하는 data_produced와 count라는 글로벌 변수를 선언했습니다.
void *consumer(void)
{
while (1) {
pthread_mutex_lock(&mutex);
while (data_produced == 0)
pthread_cond_wait(&cond, &mutex);
printf("Consumed %d\n", count);
data_produced = 0;
pthread_cond_signal(&cond);
pthread_mutex_unlock(&mutex);
}
return 0;
}
컨슈머의 경우 지속적으로 무한 루프를 돌며 데이터를 소모하는 동작을 합니다. 이 무한 루프는 critical section으로 구성되어 있는 것을 확인할 수 있습니다. 컨슈머는 우선 생성된 데이터가 있는지를 확인합니다. 데이터가 있는 경우 소모를 하고 데이터를 사용한 것을 표현하기 위해서 data_produced를 0으로 초기화합니다.
초기화를 한 다음에는 pthread_cond_signal을 통해서 버퍼가 비워있음을 알려 프로듀서를 깨워줍니다. 만약 데이터가 없는 경우는 컨슈머가 pthread_cond_wait을 통해서 waiting queue에서 대기하게 됩니다. 이때 컨슈머는 critical section에서 나오게 됩니다. (condition variable)
void *producer(void)
{
while (1) {
pthread_mutex_lock(&mutex);
while (data_produced == 1)
pthread_cond_wait(&cond, &mutex);
printf("Produced %d\n", count++);
data_produced = 1;
pthread_cond_signal(&cond);
pthread_mutex_unlock(&mutex);
}
return 0;
}
프로듀서 코드도 pthread_mutex_lock과 unlock을 통해서 critical section을 구현합니다. 프로듀서는 버퍼에 빈 공간이 있으면 waiting되고 빈 공간이 있다면 데이터를 생산하고 데이터가 생산됐다는 정보를 data_produced 변수에 넣고 컨슈머 쓰레드를 깨워줍니다..
int main(void)
{
pthread_t tid[2];
pthread_create(&(tid[0]), NULL, consumer, NULL);
pthread_create(&(tid[1]), NULL, producer, NULL);
pthread_join(tid[0], NULL);
pthread_join(tid[1], NULL);
return 0;
}
메인 함수의 동작은 컨슈머와 프로듀서를 생성하고 두 쓰레드가 무한 루프를 돌며 데이터를 생성하고 소모하는 일을 반복하게 합니다.
'CS > Operating System' 카테고리의 다른 글
| 11. Deadlock (1) | 2023.12.10 |
|---|---|
| 10. 모니터(Monitor) (1) | 2023.12.06 |
| 8. 동기화(Synchronization) (2) | 2023.11.20 |
| 7. 스케줄링(Scheduling) (2) | 2023.10.31 |
| 6. 리소스(Resource) (0) | 2023.10.24 |