
segmentation이란 하나의 프로세스가 여러 메모리 청크를 할당받아 작업하는 것을 의미합니다. 초창기 job의 경우 하나의 메모리 청크만을 할당받고 실행되었지만 메모리 청크 하나만을 할당받으면 여러 문제가 생깁니다. code 부분에 속하는 메모리의 경우 read operation만 실행하지만 data에 속하는 메모리의 경우 read와 write operation을 제공해야 합니다. (성격이 다른 두 메모리가 합쳐진 상태)
code sharing 부분에서도 문제가 발생합니다. 여러 프로세스가 동일한 exe 파일을 실행할 때 코드를 공유할 때 메모리 영역이 하나의 청크로만 구성되어 있다면 공유할 수 없는 힙과 스택 그리고 공유가 가능한 코드 영역이 합쳐져 있어서 코드를 공유하지 못합니다. (코드와 heap, stack 데이터를 담은 주소들이 서로 불연속적으로 섞여있는 상태)
이런 문제점을 해결하기 위해서 하나의 프로세스에 여러 메모리 청크를 할당하게 되는데 이것이 segmentation입니다. 이렇게 메모리 청크가 늘어나면서 OS도 점점 복잡해지는데 그 이유는 세그먼트가 한 개라면 base, bound register fair를 하나만 유지하면 되지만 여러 개의 세그먼트가 생기면 address translation을 위해서 각 세그먼트마다 base, bound register fair를 관리해야 합니다.
OS에서는 address translation 정보인 base, bound register fair를 하나의 테이블로 만들어서 여러 개로 관리하는 방식으로 진행합니다. 조금 더 자세히 말하면 메인 메모리에 세그먼트 테이블을 위치시키고 MMU가 세그먼트를 확인해서 세그먼트에 맞는 base, bound register fair를 가지고 오게 됩니다. 그래서 segmentation을 OS가 지원한다는 것은 address mapping을 어떻게 잘 진행하는지가 핵심이 됩니다.

메인 메모리에 있는 실제 D램의 바이트 주소를 피지컬 어드레스라고 부릅니다. 프로세스의 어드레스는 로지컬 어드레스라고 부릅니다. 둘 다 0에서부터 시작하지만 피지컬 어드레스의 경우 매핑 안된 부분이 비어있는 영역이 될 수 있습니다. 피지컬 어드레스가 모여있는 피지컬 어드레스 스페이스는 1개만 존재하지만 로지컬 어드레스가 모여있는 로지컬 어드레스 스페이스는 프로세스 당 1개씩 가지고 있기 때문에 훨씬 많은 양이 존재함을 알 수 있습니다.
segmentation을 지원하는 MMU의 경우 로지컬 어드레스가 이슈 되면 로지컬 어드레스 translation을 해주어야 합니다. 이런 address translation을 하기 위한 매핑 정보는 메인 메모리에 존재하는 segment table에서 base, bound register fair를 통해 진행됩니다.
segment table에 MMU가 접근하기 위해서는 먼저 segment number를 얻어와서 index로 사용해 table에서 검색을 진행합니다. 그다음에 base와 bound register fair를 가져와서 bound로 체크를 진행합니다. 확인 결과 유효한 어드레스라면 베이스 어드레스를 가져와서 나머지 세그먼트에 offest value와 더하는 일을 진행합니다.

segmentation을 지원하는 MMU 구조입니다. CPU가 프로세스를 수행시키면서 이슈한 모든 어드레스는 로지컬 어드레스로 보면 됩니다. (이슈 = CPU가 프로세스를 실행시키면서 생기는 모든 메모리 접근)
로지컬 어드레스가 피지컬 어드레스로 바뀌는 과정은 MMU를 거치는 부분이라고 보면 됩니다. MMU는 로지컬 어드레스의 상위 몇 bit를 사용해서 segment number를 획득합니다. 이후 MMU는 세그먼트 테이블에서 베이스 주소와 바운드 값을 가져옵니다. 베이스 주소가 유효한지 확인하고 유효하다면 가져온 세그먼트의 베이스 주소와 세그먼트 내의 offset을 더해서 피지컬 어드레스를 만듭니다. (offset = 로지컬 어드레스에서 segment number를 뺀 나머지 부분)
이렇게 segmentation을 지원하는 MMU는 OS가 적절히 조정해줘야 합니다. context switching이 발생할 때마다 새로 들어오는 프로세스의 segment table 주소를 MMU의 segment table base register에 넣어줘야 합니다. 그래야 그 프로세스에 맞는 정확한 매핑 정보를 얻어올 수 있습니다. segment table은 D램에 존재하는데 이 영역은 피지컬 메모리 어드레스로 액세스 하는 영역으로 address translation이 필요하지 않은 unmapped area입니다. (segment table base register = segment table을 보관하기 위한 공간)
ex)

어떻게 address translation이 동작하는지 알아보겠습니다. 이 예시는 14bit address를 가지며, 상위 2bit는 segment number로 사용되고 하위 12bit는 offset으로 사용됩니다. 상위 2bit만 사용하기 때문에 table에서 구별이 가능한 세그먼트는 4가지가 됩니다.
맨 오른쪽 부분 열은 protection bit으로 이 세그먼트에 대해 허용되는 operation을 규정합니다. RW라고 되어 있는데 R은 read operation이고 W는 write operation으로 이 부분이 1이라면 해당 operation이 가능한 것이고 0이면 불가능한 것입니다. 이를 통해서 0번 세그먼트는 read only인 code segment임을 알 수 있습니다.
2번, 3번은 stack, data segment일 확률이 높고 3번의 경우는 사용하지 않는 segment로 read와 write가 전부 불가능합니다.

위 사진은 베이스 값과 바운드 값의 매핑된 형태를 도식화한 것입니다. 오른쪽의 경우 0부터 0x4000번까지의 로지컬 어드레스 스페이스를 갖는 프로세스 입니다. 0부터 700번지의 로지컬 어드레스 부분은 D램의 피지컬 메모리에 4000번지부터 4700번지에 매핑이 되어있는 것을 알 수 있습니다. 이 과정을 MMU는 table을 통해서 진행합니다.
이전 사진에서 3개의 segment number를 얻어와서 translation하는 과정을 진행해 보겠습니다. 로지컬 어드레스 0x0240의 경우 segment number는 0이고 offset: 0x240로 segment table에서 0번째 행을 얻어보면 됩니다. 바운드 값이 0x6FF로 6FF는 240보다 훨씬 큰 값이기 때문에 read만 가능한 valid address인 걸 알 수 있습니다.
이제 그 세그먼트가 실제로 적재되어 있는 베이스 주소 0x4000을 가져와서 offset과 더하면 0x4240이 됩니다.

process memory management 관점에서 segmantation은 code sharing이나 각각의 opearation과 protection이 가능하다는 장점이 있지만 fragmentation 문제를 발생시키는 원인입니다. 피지컬 메모리 전체를 힙이라고 생각한다면 세그먼트들은 다이나믹하게 할당된 메모리로 볼 수 있습니다. 이런 메모리를 프로세스가 생성되는 과정을 반복하게 되면 굉장히 많은 hole들이 생성되게 됩니다.
fragmentation이 발생하여 메모리 공간이 없어 새 프로세스의 세그먼트를 할당할 수 없게 된다면 idle process(쉬고 있는 프로세스)들을 디스크로 swap out 시켜 공간을 확보해야 합니다.
idle process의 겨우 오랫동안 사용되지 않았으니 가까운 시간 안에 사용되지 않을 가능성이 높기 때문에 메인 메모리에서 디스크로 이동시키는데 이 프로세스의 세그먼트를 전부 swap out 시킬 수는 없습니다. 다시 요청을 받아 수행할 수 있기 때문에 필요한 양만큼의 몇 개의 세그먼트만 swap out 시킵니다. (segmentation은 필요한 세그먼트 단위로 swap in/out이 가능하다는 장점이 존재, 이전에는 나눠져 있지 않아서 불가능했음)

스택의 경우 계속 쌓이기 때문에 세그먼트도 스택과 같이 크기가 증가할 수 있습니다. 이로 인해 인접한 다른 프로세스의 세그먼트와 충돌이 발생할 수 있습니다. 이를 해결하기 위해서는 인접한 세그먼트를 swap out 시켜 빈 공간을 만들거나 stack segment를 swap out 시키고 나중에 충분한 공간이 있을 때 swap in 시키는 방법도 있습니다.
segmentation은 fragmentation이나 address translation의 속도를 2배 저하시키기 때문에 현재에는 거의 사용되지 않습니다. segmentation을 사용하던 과거에는 fragmentation을 해결해야 했는데 이때 고안된 기법이 페이징(paging)입니다.

fragmentation이 생기는 첫 번째 조건은 메모리 영역이 전부 연속적이어야 합니다. 만약 흩어져 있다면 fragmentation이 발생하지 않습니다. 두 번째 조건은 allocation unit이 고정적이지 않고 가변적이어야 됩니다. 1k, 10k, 15k 등 시기마다 원하는 크기가 각각 달라야 합니다. 크기가 다른 allocation을 동적으로 받게 되면 hole들이 점점 작아지게 되고 fragmentation이 발생합니다.
이렇게 2가지 필요조건이 만족되어야 fragmentation이 발생하기 때문에 paging은 memory allocation 단위를 uniform size로 만듭니다. 이런 일정한 단위가 바로 페이지입니다.

메모리 관리를 이야기할 때는 프로세스의 로지컬 어드레스 스페이스와 피지컬 메모리의 피지컬 어드레스 스페이스를 분리해서 생각해야 합니다. MMU와 OS를 통해서 로지컬 어드레스 스페이스의 주소들을 피지컬 어드레스 스페이스에 매핑시키는 과정도 기억해 두면 페이징을 이해하는데 도움이 됩니다.
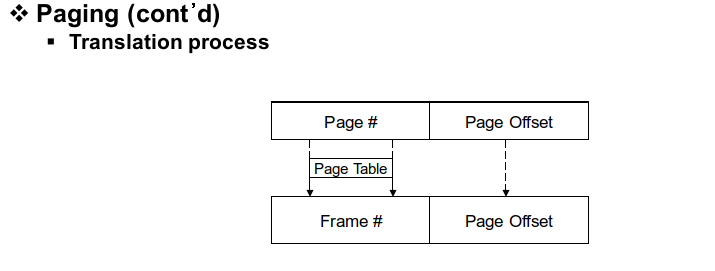
페이징에서 일정한 단위로 memory allocation을 진행하는데 이것을 로지컬 어드레스 스페이스 관점에서는 페이지라고 하고 피지컬 어드레스 스페이스 관점에서는 프레임이라고 부릅니다. 즉 페이지와 프레임은 다른 영역에서 동일한 의미를 갖는 것입니다. (페이지는 로지컬 페이지, 프레임은 피지컬 페이지 프레임이라고 부르기도 합니다.)
페이징을 하기 전 먼저 생각해야 하는 것은 페이지의 사이즈입니다. 과거에 컴퓨터 성능이 좋지 않고 메인 메모리의 사이즈가 작을 때는 페이지를 작게 만들었습니다. (0.5k, 1k, 2k, 16k 등), 요새는 페이지의 크기가 1M, 2M, 4M 이렇게 더 커지는 추세입니다.

이렇게 페이지와 프레임으로 나눠져 있는 상태에서 address translation을 진행해 보겠습니다. 처음으로 하는 일은 페이지를 프레임으로 매핑하는 작업입니다. 이 작업은 OS가 MMU의 도움을 받아 진행합니다. 페이지 넘버를 프레임 넘버에 매핑하는데 필요한 정보는 page table을 통해 얻습니다. (segmentation table과 유사, 똑같이 unmapped 영역에 존재, 만약 map 영역에 존재한다면 table에 접근하기 위해서도 translation이 필요해짐)
page table base address register가 해당 프로세스의 page table의 시작 주소를 가지고 있어야 table에 접근해서 정보를 얻을 수 있습니다. page table의 entry에는 array처럼 access 하기 때문에 table은 피지컬 메모리에 연속적으로 저장되어 있어야 합니다.
페이징을 지원하는 마이크로 프로세스 중 SPARC라는 프로세스가 있었는데 SPARC의 address bit는 32 bit로 위 사진처럼 상위 20bit을 page number로 사용하고 하위 12bit를 page offset으로 사용합니다. page number를 20bit으로 표현한다는 것은 최대 2의 20 승개의 페이지를 사용할 수 있다는 것입니다. (segment table과 다르게 2의 20승을 표현해야 하는 page table의 경우 크기가 엄청나게 커짐)
SPARC의 address는 32bit니 1 word여서 page table을 만들 때 가장 작은 사이즈가 1 word, 즉 4byte가 됩니다. 2 word나 3 word로 페이지를 만들 수 있겠지만 최대 2의 20승만큼 만들어지는 페이지는 피지컬 메모리에 상당한 부분을 차지하기 때문에 최대한 작게 4byte 안에서 패킹하는 것이 좋습니다.
사진처럼 page table에 있는 page frame에 주소를 적재하면 32bit 머신에서 주소는 32bit이니 더 이상 정보를 담을 수 없게 됩니다. 물론 page frame에 피지컬 주소를 다 넣을 필요 없이 page number인 상위 20bit만 넣으면 됩니다. frame에서 사용되지 않은 나머지 12bit는 flag bit으로 사용됩니다. (주소의 하위 12bit는 page offset으로 frame에 보관되지 않음)
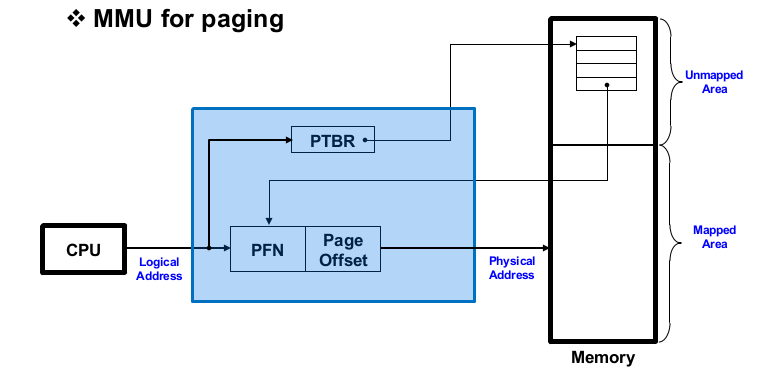
페이징을 지원하는 MMU의 모습입니다. CPU는 로지컬 어드레스를 issue 하면 이 로지컬 어드레스는 page number와 page offset 이렇게 두 가지 필드를 가집니다. 메인 메모리의 unmapped area에는 현재 수행 중인 프로세스의 page table이 존재합니다. MMU는 page table base register를 통해 page table의 base address를 가지게 됩니다.
translation 동작은 다음과 같습니다. MMU는 CPU로부터 전달받은 로지컬 어드레스에서 page number를 받고 이 값을 인덱스로 사용해서 page table을 검색합니다. 해당하는 page table entry에서 physical frame number를 가지고 와서 physical frame number 20bit와 page offset 12bit를 concatination을 합니다. (segment와 비슷한 동작)
추가적으로 중요한 부분을 이야기하자면 page table의 경우 unmapped area에 존재하여야 하며 array처럼 사용되기 때문에 array와 같이 메모리 상에 연속된 공간을 차지해야 한다는 것입니다. 이 예제의 경우 2의 20 승개의 4byte 크기의 페이지를 가지는 테이블을 메인 메모리에 올려야 합니다. (멀티 쓰레딩을 하게 된 이유 = 프로세스의 컨택스트 중 페이지 테이블만 표현하는 부분이 4MB로 상당히 큼)

마지막으로 페이징의 장단점에 대해 정리해 보겠습니다. 가장 큰 장점은 fragmentation 문제가 발생하지 않는다는 점입니다. 그리고 프로세스에게 메모리 공간을 할당할 때 전체의 공간을 주는 것이 아니라 필요한 양만큼 페이지 단위로 할당할 수 있습니다.
과거에는 segment 단위나 프로세스 전체의 이미지를 swap in/out 했지만 페이징에서는 페이지 단위로 swap in/out 할 수 있어 swapping에 대한 효율성이 증가합니다. 단점으로는 프로세스 당 page table을 유지하기 위해서 피지컬 메모리에 연속적으로 할당되는 공간이 너무 크다는 점과 segmentation과 마찬가지로 address translation을 하는 과정에서 메인 메모리에 있는 page table에 접근해야 하기 때문에 address translation 한 번당 다른 메모리 액세스 한 번이 발생한다는 것이 있습니다. (메모리 액세스 속도가 두 배만큼 나빠진다.)
'CS > Operating System' 카테고리의 다른 글
| 18. Enhancing Mechanisms (1) | 2024.01.24 |
|---|---|
| 17. Paged segmentation (0) | 2024.01.23 |
| 15. Dynamic allocation in Linux (0) | 2023.12.24 |
| 14. GNU Linker (1) | 2023.12.18 |
| 13. 힙(Heap) (1) | 2023.12.18 |