segmentation, paged segmentation 이렇게 메모리 관리 기법에 대해 공부했지만 이 방법들은 현재 OS에서 사용하지 않는 방법입니다. 현대 OS는 페이징(paging) 만을 사용해서 메모리를 관리하는데 이때 사용하는 메커니즘들에 대해서 알아보겠습니다.
페이징은 굉장히 좋은 메모리 관리 기법이지만 메모리 액세스를 할 때마다 메인 메모리에 있는 페이지 테이블을 사용한다는 점과 페이지의 크기가 작고 로지컬 어드레스 스페이스가 크기 때문에 페이지의 개수가 많아지는 문제가 존재했습니다. 추가적인 메모리 레퍼런스를 한 번 더하는 문제와 페이지 테이블의 사이즈가 커져 메인 메모리에 자리를 많이 차지하는 문제가 존재 (slow memory access, large page table)
Slow memory access

slow memory access를 어떻게 해결했는지 알아보겠습니다. 이 문제는 address translation 시에 느린 메모리(메인 메모리)에서 데이터를 가져와서 연산을 진행하여 생깁니다. 이 시간을 줄이기 위해서는 단위 메모리 액세스 시간을 줄이거나 메모리 액세스 횟수를 줄여야 합니다.
단위 메모리 액세스 시간을 줄이는 것은 해결할 수 있는 이슈가 아니기 때문에 횟수를 줄이는 방법으로 접근해야 합니다. 이렇게 접근 횟수를 줄이는 방법이 translation lookaside buffer(TLB)라는 기법입니다. TLB는 간단히 말하면 page table entry에 대한 캐시로 MMU 하드웨어가 캐싱을 관리합니다.
MMU는 CPU가 내보낸 로지컬 어드레스를 입력으로 받아 메인 메모리에 존재하는 페이지 테이블에서 정보를 읽어오기 전에 내부적으로 가지고 있는 캐시에서 해당 entry가 존재하는지 찾아봅니다. TLB에 원하는 entry가 존재한다면 메모리 액세스를 할 필요가 없어지게 되고 그러면 추가적인 메모리 레퍼런스 없이 translation이 가능하게 됩니다.
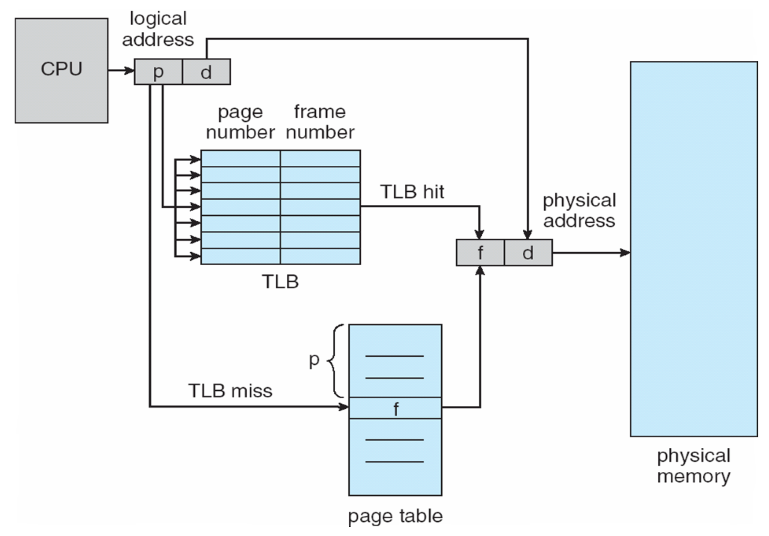
translation이 다음과 같이 TLB가 추가된 구조로 진행되게 됩니다. TLB에 원하는 정보가 있을 경우 hit가 난 것이고 없을 경우 miss가 난 것입니다. TLB hit가 나면 추가적인 메모리 레퍼런스 없이 프레임 넘버를 가져다가 피지컬 어드레스를 만들 수 있습니다. 이 구조가 잘 동작하게 되면 메모리 액세스의 성능 저하를 상당히 막을 수 있습니다. (TLB hit가 많이 일어나야 함)

다음과 같은 간단한 수식을 통해서 메모리 레퍼런스를 할 때마다 effective memory access time을 계산할 수 있습니다. 여기서 중요한 척도는 hit ratio입니다. effective memory access time 작게 만들고 싶다면 hit ratio를 크게 만들어야 합니다.

TLB 구성에 대해서 알아보겠습니다. TLB는 page table entry를 가지고 있으며 page number를 넣어주면 frame number를 출력하는 동작을 합니다. TLB 안에 페이지 테이블이 존재하고 로지컬 어드레스가 들어올 때 페이지 넘버를 얻어서 하나하나 비교하는 방식으로 처리하는 것이 아니라 direct mapped cache나 fully associative cache, set associative cache를 사용합니다.

TLB의 hit ratio는 상당히 높습니다. 코드가 어떤 페이지를 액세스 할 때 그 페이지를 지속적으로 액세스 할 가능성이 높습니다. 그래서 처음에만 메인 메모리에 있는 페이지 테이블을 look up 하고 나머지는 TLB에 로드된 페이지 테이블만 사용하기 때문에 hit ratio가 높습니다.

TLB를 자세히 알아보기 위해서 MIPS라는 마이크로 프로세서로 설명해보겠습니다. 위 사진은 TLB의 각 라인의 포맷으로 첫 번째로 페이지 넘버가 그다음 페이지 프레임 넘버 이후 여러 비트들이 TLB의 entry에 존재하는 것을 보여줍니다.
페이지 테이블에는 페이지 넘버는 인덱스로만 사용되고 entry로 프레임 넘버만 존재했었는데 TLB에서는 둘 다 entry로 존재합니다. 이 구성는 캐시 메모리의 특징으로 캐시 메모리의 경우 주소에 의해서 검색되지 않고 콘텐츠에 의해 검색되기 때문에 다음과 같은 구성을 띕니다.
캐시에 내가 원하는 정보가 있는지 확인할려면 내 정보와 캐시 메모리에 저장된 정보를 키워드 매칭을 해야 하기 때문에 버추얼 페이지 넘버(VPN)가 존재하는 것입니다. 나머지 bit에 대해서도 알아보겠습니다.
G라는 플래그는 global의 의미로 모든 프로세스의 어드레스 스페이스에 공통적으로 매핑되어 있는 페이지임을 나타냅니다. 예시로 linux OS에서는 리눅스 커널이 모든 프로세스의 일정 영역에 매핑되어 있습니다. V는 해당 페이지가 swap out 된 상태가 아니라 피지컬 메모리에 있다는 것을 표현해 줍니다.
D는 해당 페이지가 디스크에서 swap in 되고 콘텐츠가 modify 되었다는 것을 의미합니다. 반대는 클린 페이지(clean page)로 디스크에 있는 원본과 동일하다는 것을 의미합니다. 이를 통해서 클린 페이지의 경우 swap out 될 때 디스크에 있는 정보와 다르지 않기 때문에 디스크 오퍼레이션을 할 필요가 없어지게 됩니다. (디스크 오퍼레이션에 대한 성능 향상)
N bit는 해당 페이지에 있는 내용들에 대해서 캐시를 사용하지 말라는 것을 컴퓨터 시스템에 알려줍니다. shared page에 데이터를 기록하는 A 프로세스와 데이터를 읽고 있는 B 프로세스가 존재할 때 B 프로세스가 캐시를 하게 되면 과거의 데이터를 계속 활용하여 계산을 하게 되므로 inconsistemcy가 발생하게 됩니다.
이런 문제를 해결하기 위해서 버스 마스터들이 shared page에 대해서는 N bit를 1로 바꿔 캐싱을 사용하지 않게 하는 경우가 종종 있습니다. 이렇게 구성된 TLB를 MIPS R2000/R3000 머신에서 벤치마킹 했을 때 hit ratio가 98%가 나왔습니다. 이때 TLB에 64 ~ 128개의 entry만 넣은 상태였습니다. (64~128개의 entry로 100번 중 98번을 절약한 것으로 굉장히 효과적)
TLB는 하드웨어적으로 구현되며 OS가 관리하게 됩니다. 처음 액세스할 때 TLB에 miss가 계속 발생하지만 일정 시간이 흐르면 64개의 entry가 다 차게 됩니다. 이때 context switching이 발생하여 새 프로세스가 들어오게 된 경우 MMU는 프로세스가 교체되었는지 알 수 없습니다. 과거의 존재하던 TLB entry들을 사용하여 address translation을 진행하게 됩니다. (이전 프로세스의 entry로 매핑하기 때문에 엉터리 값이 나오게 됨)
이런 문제를 해결하기 위해서 OS가 context switching이 발생했을 때 TLB의 entry를 전부 incalidate 시켜줍니다. 그러면 새로 들어온 프로세스에 대해서 TLB miss가 발생하면서 entry 값들을 채우게 됩니다. (TLB를 사용하더라도 처음에는 굉장히 많은 miss가 발생하여 메모리 레퍼런스의 성능이 저하된다.)
MIPS에서는 이 문제를 TLB entry의 bit 중 하나인 PID bit을 통해서 해결합니다. 현재 수행 중인 프로세스의 ID를 기록함으로 써 해당 TLB entry가 실행 중인 프로세스에서 나온 것인지 아닌지를 확인할 수 있습니다. TLB hit가 발생하기 위해서는 페이지 넘버로 같아야 하고 PID도 같아야 하니 context switching이 발생한 경우 PID가 달라 miss가 발생하면서 overwrite 하게 됩니다. (invalidate와 같은 효과를 얻음)

TLB의 성능은 뛰어나지만 TLB를 도입하면 여러 복잡한 문제들이 생깁니다. 컴퓨터 시스템에서 가장 어려운 이슈가 동일한 데이터에 대한 카피가 생기는 것입니다. 어떤 데이터에 대한 카피가 생겨 2개 간의 consistency를 유지시키는 것은 굉장히 어렵습니다.
TLB의 경우도 메인 메모리에 page table entry가 있는데 그것의 카피를 또 MMU 내부 캐시에 넣는 것입니다. 이때 이 consistency를 잘 관리해야 될 필요가 있습니다. consistency를 관리할 때 소프트웨어적인 방법이 있고 하드웨어적인 방법이 존재합니다.
먼저 소프트웨어적인 방법에 대해서 알아보겠습니다. MMU가 TLB 검색 시 miss가 발생하게 되면 수행을 중단하고 OS에게 software interrupt를 걸어줍니다. 그러면 OS가 해당 page table entry를 메인 메모리에서 읽은 다음 TLB에 넣어주는 기능을 수행하게 됩니다.
하드웨어적인 방법은 TLB miss를 하드웨어적으로 조절하는 방법으로 OS가 TLB의 내부 동작을 볼 수 없습니다. 하드웨어적인 TLB 관리는 굉장히 빠르고 OS에게 tramsparent 하다는 장점이 있지만 handling을 위해서 하드웨어가 page table의 위치를 전부 알고 있어야 되고 page table format까지 이해하고 있어야 한다는 단점이 존재합니다.

다음으로 페이징을 사용할 때 OS 운영 상에서 발생할 수 있는 여러 이슈들에 대해서 알아보겠습니다. 먼저 DMA 오퍼레이션이 발생했을 때 페이징에 주는 영향입니다. 10개의 페이지에 해당하는 데이터 블록을 디스크에 있는 파일에 write 한다고 해봅시다. 그러면 write system call을 하게 되고 DMA 오퍼레이션이 발생하게 됩니다.
DMA 오퍼레이션의 파라미터는 DMA의 대상이 되는 시작 주소와 데이터 블록의 시작 주소 그리고 사이즈가 됩니다. 10개의 연속적인 10개의 페이지를 write 할 때 실제로 10개의 페이지가 연속적이지 않을 수 있습니다. 로지컬 어드레스 스페이스에 있는 페이지들은 실제 피지컬 메모리에 어느 페이지 프레임에 할당될지 모르기 때문입니다. (DMA는 모든 데이터 브록이 연속적으로 있다고 생각하여 시작 주소와 사이즈만 받음)
그래서 이 오퍼레이션을 10개로 나눠서 처리하게 됩니다. (하나의 DMA가 10개의 페이지를 처리하는 것이 아니라 10개의 DMA가 각각 1개의 페이지를 처리하는 방식), 다음 문제는 DMA 컨트롤러는 피지컬 어드레스가 필요하다는 점입니다. DMA 컨트롤러는 MMU를 거치지 않기 때문에 로지컬 어드레스를 이해할 수 없습니다. 그래서 OS가 사용자의 로지컬 어드레스를 피지컬 어드레스로 매핑시킬 수 있어야 합니다.
여태까지 로지컬 어드레스를 피지컬 어드레스로 변경하는 작업은 MMU가 진행했지만 OS도 페이지 테이블이 어디에 있는지 알고 있기 때문에 OS도 address translation이 가능합니다.

로지컬 어드레스는 프로세스들에게 부여된 주소로 사용자의 코드는 로지컬 어드레스 스페이스 상에서 수행이 됩니다. 여기서 두 번째 이슈가 발생하는데 유저 스페이스가 커널 모드로 들어가서 커널 함수를 수행하게 되면 커널 함수는 어떤 스페이스 상에서 수행이 되는지입니다. 이 부분은 OS코드 전체를 unmapped 영역에서 수행하게 하면 됩니다. 또는 유저 프로세스의 로지컬 어드레스 스페이스의 일정한 영역에 OS를 매핑시켜서 수행시켜도 됩니다.
unmapped memory는 굉장히 제한되어 있기 때문에 OS 사이즈가 커진다면 확장이 불가능하게 됩니다.
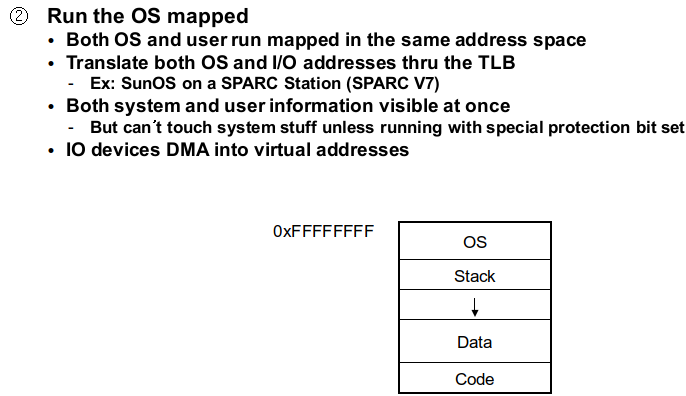
만약 OS를 별도의 어드레스 스페이스에 매핑시키게 되면 유저 프로세스가 시스템 콜을 호출했을 때 어드레스 스페이스가 체인지 변경되는 매핑으로 인해서 오버헤드가 발생할 수 있습니다.
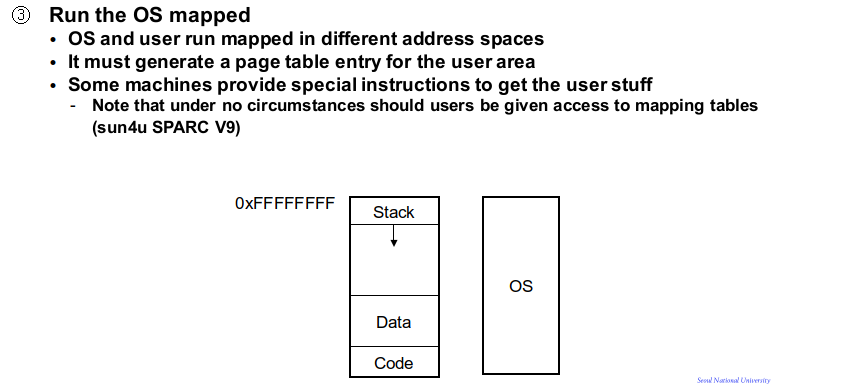
마지막으로 OS를 유저 영역에 매핑시키는 기법으로 linux 같은 OS가 사용하는 방법으로 가장 자주 사용되는 방법입니다. 로지컬 어드레스 스페이스 일정한 영역에 리눅스를 매핑하는 것입니다.
'CS > Operating System' 카테고리의 다른 글
| 20. Demand Paging (2) | 2024.01.26 |
|---|---|
| 19. Memory Management Mechanism (1) | 2024.01.25 |
| 17. Paged segmentation (0) | 2024.01.23 |
| 16. Segmentation (1) | 2024.01.10 |
| 15. Dynamic allocation in Linux (0) | 2023.12.24 |