모델 사이즈와 데이터 셋 사이즈가 증가함에 따라 학습의 효율성은 더 중요해집니다. GPT-3는 큰 모델과 많은 학습데이터로 few shot learning에서 좋은 성능을 보여주지만 학습하기 위해서는 몇 주의 훈련과 많은 TPU를 요구하기에 성능을 더 개선시키거나 retrain하기가 어렵다는 점에서 training efficiency의 중요성을 알 수 있습니다.
이 논문은 이전 EfficientNetV1에서 생겼던 문제점들을 해결하여 더 빠른 학습 속도와 더 좋은 파라미터 효율을 가진 모델 EfficientNetV2를 소개하고 있습니다.
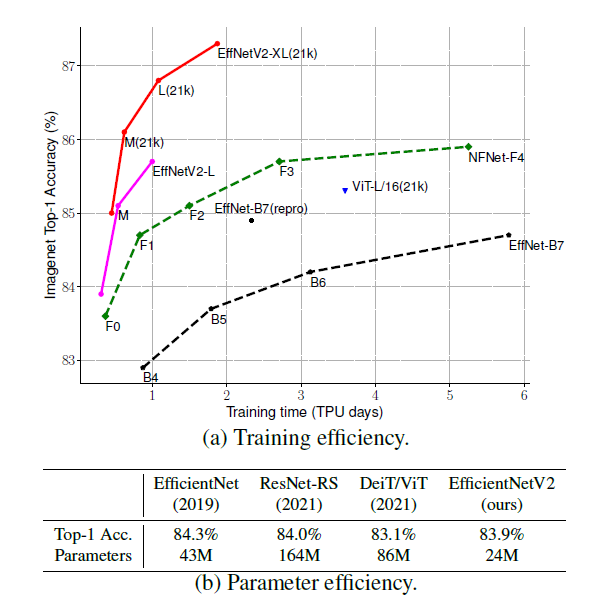
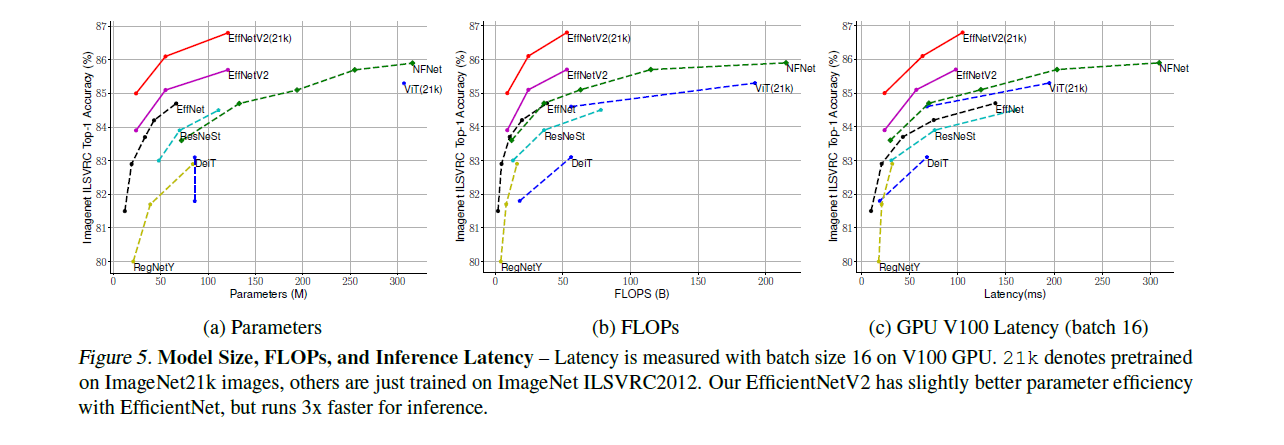
그래프를 통해 다른 모델과 비교했을 때 EfficientNetV2가 5~11배 더 빠른 학습 속도와 더 좋은 파라미터 효율을 보여주는 것을 알 수 있습니다. 다른 모델들은 attention layer를 추가하여 학습 효율을 향상시키거나 Transformer block을 사용하는 것으로 학습 효율을 향상시키는데 이 방법들은 파라미터 효율이 좋지 않습니다. 그래서 본 논문에서는 EfficientNetV1에서 파라미터 효율을 높이기 위해 연구를 진행했고 찾은 문제들과 해결 방안은 다음과 같습니다.
1. Depthwise convolution은 앞쪽 레이어에서 느리다.
- 초기 레이어에서 MBConv 대신 Fused-MBConv로 교체(전부 교체했을 때 오히려 성능이 내려감)
2.모든 stage에서 같은 scaling을 하는 것은 완벽하지않다.
- non-uniform scaling을 사용
3. 해상도가 큰 이미지를 사용할 경우 정확도가 좋아지지만 학습 속도가 느려진다.
- 학습 중에 이미지 사이즈와 regularization을 조절하도록 바꿈 (Progressive Learning)
Fused MBConv

EfficientNetV1 같은 경우에는 모든 층에 MBConv를 사용했는데 위 사진을 보면 알 수 있듯이 MBConv 구조에 depthwise conv가 존재하는데 일반적인 convolution보다 더 적은 파라미터와 연산량을 가지고 있지만 종종 modern accelerators를 완전히 활용하지 못하기 때문에 속도가 느려지게 됩니다. 그래서 최근에 mobile, server accelerators에 더 좋게 활용 되었던 Fused MBConv를 추가하였습니다.
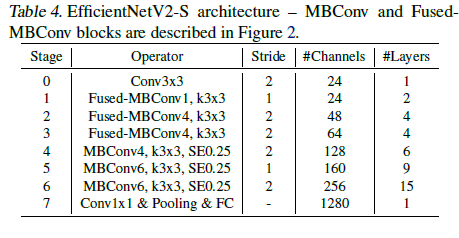
초기 1~3 레이어에서는 Fused MBConv를 사용해 학습 속도를 향상시켰지만 전부Fused MBConv로 교체하면 파라미터, 연산량 증가가 나타나서 다음과 같은 구조로 설계가 됬습니다. EfficientNetV2는 작은 expansion ration를 사용하여 memory overhead를 줄여줍니다. 커널 사이즈가 3x3이기 때문에 더 많은 층을 쌓아 receptive field를 유지해줍니다.

- modern accelerators가 무엇이고 depthwise conv가 이걸 사용하지 못하는 이유는?
EfficientNetV2 Scaling
논문에서는 이전 EfficientNetV1에서는 compound scaling을 사용하여 모든 스테이지를 동일하게 scailng up했습니다. 하지만 각 스테이지들이 학습 효율을 향상 시키는 정도가 다르기 때문에 동일하게 하는 방법으로는 최적의 비율을 찾기 어렵습니다. 그렇기에 non-uniform scaling 전략을 사용합니다. non-uniform scaling 전략은 스테이지가 증가할 때 레이어의 증가량을 높인 것입니다(heuristic하게 증가량 결정). compound scailng으로 확장되는 이미지의 maxumum값은 메모리 효율과 학습 속도를 위해서 480으로 제한합니다.
- 이미지 사이즈 제한이 480인 이유는?
- FixEfficientNet에서 최종 이미지 사이즈를 학습 때 475 x 475로 하고 추론 때 600 x 600 해상도로 학습해서 SOTA를 찍었는데 그것과 연관이 있는지?
Progressive Learning
위에서 문제점으로 지적한 것과 같이 이미지 크기는 상당한 메모리 사용량을 보여줍니다. GPU나 TPU 용량에 한계가 있기 때문에 이미지 크기가 커지면 배치 사이즈를 줄여야 했고 이 때문에 훈련 속도가 느려지는 현상이 생겼습니다.

이전 모델들에서도 이 문제로 인하여 FixRes를 적용하여 학습 중 이미지 크기를 바꾸는 방법을 사용했지만 정확도가 떨어졌습니다. 본 논문에서는 학습을 할 때 이미지 크기가 바뀔 때 regularization 강도 그에 맞춰서 변경되지 않아 정확도가 떨어진다고 생각했고 이를 입증하기 위해서 search space에서 추출된 모델에 적용했습니다.
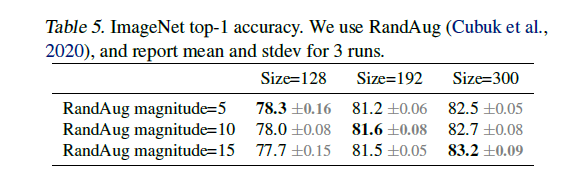
이미지가 클 때 더 강한 regularization을 한 경우 더 좋은 성과를 보여주는 것을 볼 수 있습니다. 이 내용을 토대로 학습 초기에 작은 이미지와 약한 regularization을 하여 단순한 표현을 빠르게 배우고 서서히 이미지 크기를 증가 시켜 학습을 더 어렵게 만드는 방법을 사용합니다.

본 논문에서 사용하는 정규화는 Dropout, RandAugment, Mixup 이렇게 3가지 정규화를 사용합니다.

결과
Progressive learning을 ResNets에 적용한 결과로 학습 시간이 감소한 모습을 볼 수 있습니다.
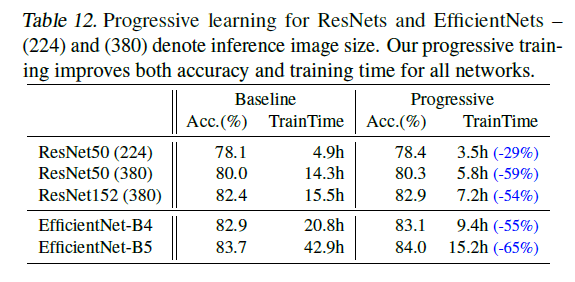
- 모르는 단어: training-aware NAS
'논문 리뷰 > 경량화 논문 스터디' 카테고리의 다른 글
| [논문 리뷰] GhostNet: More Features from Cheap Operations, CVPR 2020 (0) | 2021.10.06 |
|---|---|
| [논문 리뷰]AdderNet: Do We Really Need Multiplications in Deep Learning?, CVPR 2020 (0) | 2021.09.29 |
| [논문 리뷰] 경량화 기술 동향 (0) | 2021.09.21 |
| [논문 리뷰]Rethinking the Value of Network Pruning, ICLR 2019 (0) | 2021.09.06 |
| [논문 리뷰]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2021.08.17 |