[이 카테고리의 글들은 홍성수 교수님의 운영체제의 기초 강의를 듣고 작성했습니다.]
OS 분야의 진화는 크게 3단계로 나눌 수 있습니다.
- early ’50s – mid ‘60s: OS가 사용되지 않았지만 사람들이 필요성을 느낀 시기입니다.
- mid ’60s – mid ‘90s: 현재 사용되는 Modern OS로 넘어가는 시점입니다. 가장 OS 연구가 활발했습니다.
- mid ‘90s – present
Phase 1
첫 번째 시기에는 펜실베니아 대학교에서 ENIAC이 발명되었습니다. 이때 CPU를 구성하기 위해서 진공관이라는 굉장히 오래된 Electronic device를 사용했습니다. ENIAC은 굉장히 많은 전력을 소모했기 때문에 사람들은 컴퓨터 시스템을 운용할 때 가장 중요하게 생각했던 것이 시스템의 utilization을 극대화시키는 것이었습니다. (utilization = 유의미한 연산 / 시스템 동작 시간)
- 전기가 들어와서 컴퓨터가 동작하는 시간에 유용한 연산을 하는 시간을 늘리는 것이 목표
- utilization을 100% 달성하는 것이 목표였지만 컴퓨터 시스템을 자유롭게 운영하고 사용자들에게 편리성을 제공하는 OS의 기능이 존재하기 않았기 때문에 불가능했습니다.

이 시기에 하드웨어는 위 사진과 같이 Human Operator가 시스템의 역할을 하면서 컴퓨터 시스템을 구동했습니다. (우리가 Window OS를 사용하여 바탕화면에 응용프로그램을 누르면 실행되는 과정을 사람이 진행함)
지금은 프로그램을 작성한다고 하면 문서 편집기를 열고 거기서 작성하겠지만 초창기에는 Card에 프로그램의 Character를 입력해야 했습니다. 원하는 Character Pattern을 입력하기 위해서 Card Puncher 장비를 사용했습니다. 이렇게 Puncher를 사용하여 프로그램의 각 줄을 한 장의 카드에 작성하면 여러 장의 카드가 쌓이게 되는데 이걸 Card Deck이라고 불렀습니다.
이 Card Deck을 Human Operator에게 전달하면 라이브러리 함수에 해당하는 Card Deck을 붙여서 Card Reader라는 기계적 장치에 걸어 프로그램을 실행시켰습니다.(빛을 쪼여서 Character Pattern을 입력받아 메인 메모리에 적재가 되면서 프로그램이 로딩 됩니다.)
이러한 과정을 거쳐 프로그램을 실행시키게 되면 컴퓨터 시스템의 Utilization이 굉장히 낮게 나옵니다. 일단 메모리에 로드가 되고 출력할 때 과정이 사람의 손동작으로 이루어지며 Card Reader가 컴퓨터와 비교했을 때 많이 느렸습니다. 그래서 한 Job이 끝나고 다른 Job이 들어올 때까지의 시간이 오래 걸렸습니다. 이런 것을 Slow job-to-job transition이라고 이야기합니다.
이러한 문제를 해결하기 위해서 컴퓨터 엔지니어들은 Card Deck을 여러 벌 묶어서 Card Reader에 걸어 컴퓨터가 여러 개의 Job을 읽을 수 있게 했습니다.
- 메인 메모리는 한 번에 한 개의 Job을 진행하기 때문에 한꺼번에 Card Reader를 읽어서 마그네틱 저장장치에 기록하게 됩니다. (테이프 드라이브에 저장)
- 여러 개의 Job을 한꺼번에 묶어서 테이프 드라이브에 저장하는 것을 batch라고 합니다.(batch Job을 진행하는 펌웨어가 batch monitor)
- 또한 SPOOL이라는 기법을 도입하여 job-to-job transition 시간을 크게 줄였습니다.
이 기능들을 구현하기 위해서는 메인 메모리에 상주하는 펌웨어 batch monitor가 필요하게 되는데 이것이 바로 OS의 효시입니다.

이후에 또 다른 Utilization이 낮아지는 또 다른 문제가 발견되었는데 I/O Device를 CPU가 하나하나 제어하고 관리하면서 생기는 문제였습니다. I/O Job을 시행할 때 CPU가 어떤 다른 일도 하지 못하기 때문에 엔지니어들은 CPU연산과 I/O연산을 병렬로 실행하는 방법에 대해 고민했습니다.
이 문제를 해결하기 위해서 CPU와 I/O Device를 분리하기 시작했습니다. IBM에서 하드웨어적인 서킷을 하나 만들었는데 그것을 I/O 채널이라고 부릅니다. 이 I/O 채널이 CPU를 대신해서 I/O Job을 통제했습니다. CPU는 I/O 채널에게 입력을 할 것인지 출력을 할 것인지 명령을 내리고 데이터를 전달하면 됩니다.
I/O 채널이 I/O연산을 모두 진행했거나 실패했을 때 CPU에게 결과를 알려줘야 하는데 이것이 interrupt mechanism입니다. IBM에서 I/O 채널과 interrupt mechanism을 컴퓨터 시스템에 도입해서 Utilization을 높인 것이 두 번째 시기의 가장 중요한 기술적 진보입니다.
하지만 이렇게 하드웨어적인 조치를 취했다고 해서 I/O연산을 모두 CPU연산과 병렬화시킬 수는 없습니다

I/O 연산은 Async와 Sync로 나뉘는데 Async의 경우 CPU가 I/O채널에게 I/O연산을 던져주고 바로 다른 Job을 진행하지만 Sync의 경우 I/O가 끝나서 온 데이터를 활용해서 연산하는 Job이기 때문에 입력된 데이터와 내 코드가 Data dependency를 가지게 됩니다.
- 두 번째 시기에는 Batch Monitor에 I/O채널과 interrupt mechanism을 추가하여 Async I/O의 경우 병렬화를 성공했다고 생각하면 됩니다.
- Advanced SPOOLing을 Operating System이 Support 하기 시작을 했습니다. SPOOLing의 경우 데이터를 임시 저장소에 저장한 후 한 번에 처리하지만 Advanced는 데이터를 여러 section으로 나눠서 처리함으로써 데이터가 많더라도 성능 저하가 없습니다.(Async 병렬처리에도 도움을 줍니다.)
Advanced Batch Operating System의 등장

이 당시 사용되는 컴퓨터에 메모리 레이어는 위 사진과 같습니다. 메모리 한쪽 구석에는 여러 가지 Batch Monitoring을 담당하는 OS가 상주하게 됩니다. 나
머지 영역에는 고정된 주소로 유저의 코드를 로드해서 수행시킬 수 있습니다. 한 개의 Job씩 모니터가 적재하고 수행시키고 출력을 내며 다시 새로운 Job을 적재하는 이런 일들을 수행할 수 있습니다.
어떻게 Sync I/O 병렬화를 할까?

멀티 프로그래밍이 해결책입니다. 멀티 태스킹이 CPU의 관점이라면 멀티 프로그래밍은 메모리의 관점입니다. 컴퓨터 메모리에 아직 수행이 종료되지 않은 액티브한 Job들이 여러 개가 탑재되어 수행되는 것입니다. 메인 메모리에 Job이 여러 개가 들어가는 것입니다.
- 여러 개의 Job을 메인 메모리에 올리고 서로 CPU를 주고받으면서 수행하게 되는 형태
하지만 이런 멀티 프로그래밍을 구현하는데 3가지 중요한 이슈가 존재했습니다.
- Memory Protection issue
- Relocation issue
- Concurrency Control issue
Memory Protection

이 컴퓨터 시스템에서는 3개의 job이 실행되고 있습니다. job1이 수행되고 있는데 job1에 포인터 버그가 있었습니다. 잘못된 주소값을 가리키고 있는 것입니다. 그 잘못된 영역은 job2의 영역입니다. job1은 잘못된 포인트에 내용을 교체하는 overwriting을 수행합니다.
이 경우 job2의 데이터가 corrput(부정확) 해지는 문제가 생기게 됩니다. 이 경우 job2를 수행되다 corrupt 된 데이터를 터치하게 되면 error가 발생하게 됩니다. 이게 memory protection에 문제입니다. (job1이 영역을 벗어나서 발생한 문제)
이전 simple batch monitor에서는 한 개의 job만 수행했기 때문에 버그가 발생하지 않았습니다. 원래는 프로그램의 시작 주소를 고정해 놓고 instruction과 데이터의 주소를 다 부여했지만 멀티 프로그래밍에서는 여러 개의 job이 수행되니 오로지 첫 번째의 job만 고정된 주소에서만 수행이 가능하고 나머지 job은 어디서 수행될지 알 수가 없었습니다.

Relocation이란 작성한 프로그램이 메인 메모리의 어떤 임의의 위치에 load가 되어도 수행이 될 수 있도록 하는 것입니다. Multiprogrammed Batch Operating System을 만들려면 Relocation과 Memory Protection의 문제를 해결해야 합니다.

Base register는 어떤 job의 시작주소를 담고 있는 register를 의미합니다. 위 사진의 job2를 보면 2500번이 시작 주소이고 이 register가 job2의 base register입니다. bound register는 현재 수행되는 job의 사이즈를 담고 있는 곳입니다. (끝 주소 - 시작 주소), job2의 사이즈는 4000 - 2500으로 1500이 나옵니다.
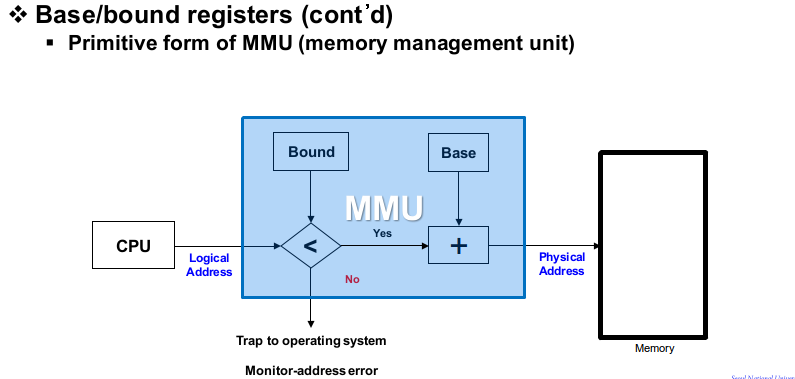
과거의 프로그래머들은 내 프로그램이 Physical memory의 몇 번에 load 될지 다 알고 주소를 부여했지만 이제는 그렇지 않습니다. 현재 모든 프로그래머들은 프로그램을 할 때 내 프로그램이 0번지에 적재될 것이라고 생각하며 코딩을 합니다. 그러면 모든 데이터 주소와 instruction 주소가 모두 0에서부터의 상대주소가 됩니다.
이렇게 프로그램이 메인 메모리에 적재가 되고 프로그램을 수행시키기 위해서 CPU가 첫 번째 instruction을 fetch 해와야 합니다. 이때 제일 먼저 이 instruction의 주소가 job의 사이즈보다 작은 지를 검토합니다, bound register의 값과 instruciton의 주소를 비교하는 것입니다. 만약 instruction의 주소가 더 크다면 protection error를 만들고 있는 job임을 판별할 수 있습니다. (이후 OS가 다른 데이터를 corrupt 시키지 못하게 termination 시켜버림)
- 멀티 프로그래밍을 하기 위해서는 Logical address 개념이 필요하고 Logical address를 Physical address로 변환해 주는 과정이 필요하다. (이런 변환을 담당해 주는 유닛이 Memory Management Unit, MMU)
- 이런 MMU의 기능은 소프트웨어, 하드웨어 두 곳에서 다 구현할 수 있는데 하드웨어로 구현하는 것이 더 합리적이기 때문에 반드시 하드웨어로 구현해야 합니다.(받아들일 수 없을 정도의 오버헤드가 발생하기 때문)
Concurrency control

두 개의 job이 다른 CPU에서 동시에 수행되고 있을 때 공유하는 정보를 서로 읽고 쓰는 행동을 하게 되면 그 값이 엉망이 돼버리는 문제, 혼자서 읽었으면 상관이 없는데 둘이 동시에 공유하고 있는 자료를 읽고 수정하면 발생하는 문제입니다.
Phase 2
두 번째 시기에서는 하드웨어 가격이 저렴해지게 됩니다. 비싼 진공관 대신에 트랜지스터를 사용하여 CPU를 설계하기 때문입니다. I/O Device나 메모리의 경우에도 반도체를 사용하여 저렴하게 만들 수 있었습니다. 대신에 인건비가 비싸졌기 때문에 사람들의 시간을 최대한 효율적으로 활용하게 하는 것이 중요하게 됩니다. Time sharing Operating system이 등장하게 되는데 이 컴퓨터 시스템을 사용하게 되면 배치 컴퓨터와 다르게 여러 개의 터미널을 동시에 서비스할 수 있습니다.
Time sharing Operating system은 각 터미널의 유저들에게 CPU를 Multiplexing(다중화)하는 형태로 사용이 됩니다. 컴퓨터의 CPU time을 잘게 쪼개서 여러 터미널 유저에게 나누어주는 형식으로 진행됩니다. 이때 컴퓨터의 성능을 측정하는 척도가 바뀌게 되는데, 다른 사람들의 Job들을 끝내서 Throughput이 높은 것보다 내가 시킨 job에 대해서 얼마나 빠르게 응답하는 것이 중요하기 때문에 reponse time이 중요한 척도가 됩니다.
Phase 3
야후라는 인터넷 기업이 등장하면서 World Wide Web(WWW)에 대한 검색이 쉬워지면서 자료들이 많이 올라오기 시작합니다. 과거에는 단순한 형태인 텍스트나 바이너리만 존재했는데 이제 멀티미디어 데이터(동영상, 음원 파일)가 등장합니다. 개인용 컴퓨터가 흔해지고 그 컴퓨터들이 connected 되었다는 것이 이 시기의 가장 큰 특징입니다.
옛날 컴퓨터는 데이터 처리만 잘했으면 됐지만 이제는 다양한 인터넷 액세스를 지원하는 OS와 다양한 미디어를 지원하는 OS 등 다양한 기능들을 요구하게 됩니다. Phase 2까지는 discrete 데이터만 처리했지만 Phase 3에서는 continuous 데이터를 잘 인식하기 위해서 CPU의 일정 부분을 주기적으로 할당해 주는 Bandwidth Scheduling이란 기능을 제공해 주기 시작합니다.
OS의 특징
굉장히 방대한 시스템
- OS가 방대해진 이유는 최근 하드웨어가 발전하면서 기능 자체가 복잡해졌고 또 하드웨어 종류가 다양해졌기 때문에 그렇습니다.
- 이렇게 크고 복잡하다 보니 내부를 이해하는 것이 어렵습니다.
- 사람들이 만든 OS 기능들은 굉장히 다양한데 이 여러 기능들이 한꺼번에 존재하고 서로 Asynchronous 하게 동작하다 보니까 그 기능과 기능들이 어떤 behavior를 보일지 예측하기가 어렵습니다.
OS의 기능
- Coordinator: 하드웨어 리소스를 종류별로 잘 관리해서 여러 job들이 효율적이게 사용할 수 있도록 조정하는 기능
- Illusion Generator: 복잡한 하드웨어 기능 대신에 사용자들이 사용하기 편한 Virtual machine을 제공해 줍니다.
- Standard Library: 다양한 사용자들이 사용할지 모르는 기능들을 구현해서 API로 제공해 줍니다.
Coordinator 중 CPU를 관리하는 Process management 부분에서는 Multitasking이 중요합니다. Mutltasking의 목적은 concurrency를 제공하는 것입니다. Memory management는 multiprogrammed batch를 지원하기 위해 Logical address를 Physical address로 변환하는 Job을 제공해 줍니다.
'CS > Operating System' 카테고리의 다른 글
| 6. 리소스(Resource) (0) | 2023.10.24 |
|---|---|
| 5. 멀티 쓰레딩(Multi Threading) (2) | 2023.10.17 |
| 4. Process (creation, termination, context switching) (0) | 2023.10.12 |
| 3. 스택(Stack) (2) | 2023.10.01 |
| 2. System bus, Duel mode (0) | 2023.09.30 |