의사결정나무(Decision Tree)는 머신러닝의 학습 알고리즘으로 방정식 형태가 아닌 트리 형태의 목적함수를 가집니다.

위 사진처럼 트리 형태로 데이터를 분류하는데 각각의 질문이 담긴 부분을 node라고 하며 해당 질문에 True, False를 나타내 주는 화살표를 edge라고 하며 최상위 node를 제외한 층수를 depth라고 합니다. 위에 결정트리는 독립변수가 수치형으로 이루어진 트리이고 범주형으로 이루어진 형태도 존재합니다.
첫 부분에서 결정트리는 방정식 형태가 아니라고 했었는데 그 이유는 이전의 선형회귀 처럼 가설 함수가
- 모든 데이터가 단일 클래스로 분할되는 순간 학습이 종료됩니다. 질문의 순서는 최종 결정에 도움이 많이 되는 질문부터 던집니다.
알고리즘
결정트리는 몇 가지 알고리즘을 통해서 조금 더 디테일하게 조정할 수 있습니다.
- 불순도 알고리즘
현재 집단에 어느 정도 다른 객체들이 섞여있는지 확인하고 불순도가 낮은 쪽으로 가지를 형성하게 합니다.
엔트로피(Entropy)는 다지 분리(multiple split) 불순도(Impurity)는 2진 분리를 합니다.
1. C4.5 알고리즘
Entropy 값이 작을수록 불순도가 낮다고 해석하는 방법입니다.
2. CART(Classification And Regression Trees) 알고리즘
Gini 값이 작을수록 불순도가 낮다고 해석하는 방법입니다.
- 정보 획득(Information Gain)
정보의 가치를 의미하는 값이 클수록 좋다는 것을 의미합니다. 사전 엔트로피와 사후 엔트로피의 차로 얼마나 불순도가 줄어들었는지로 해석할 수 있습니다. 값이 큰 경우 불순도가 많이 감소하여 엔프로피가 작으므로 제대로 분류했다는 것을 알 수 있습니다.
SVM(Support Vector Machine)
SVM은 선형, 비선형 분류 및 회귀와 이상치 탐색에도 사용할 수 있는 다목적 머신러닝 모델입니다. 고차원 데이터의 분류문제에 좋은 성능을 보입니다.
- 결정경계(Decision Boundary)
SVM은 주어진 데이터가 어느 카테고리에 속할지 분류하는 모델, 분류를 위한 기준 선인 결정경계를 정의하는 모델.
데이터에 2개 feature만 있는 경우 결정경계는 아래 사진과 같이 직선 형태를 띠게 됩니다.
데이터에 3개의 속성이 있는 경우 결정경계는 평면 형태의 Decision boundary가 됩니다.
3차원 공간에서 2차원 평면, 즉 데이터 속성의 수보다 한차원 낮은 공간인 초평면이 Decision boundary가 됩니다.
하지만 이렇게 데이터를 나눈다고 한다면 가능한 case가 너무 많아집니다.
위 사진과 같이 다양한 case가 있는데 여기서 optimal solution을 찾기 위해서 마진(Margin)이라는 개념을 도입하게 됩니다.
Margin
이 마진은 최적의 Decision boundary를 구하는 SVM의 기준이 됩니다. 마진은 다음과 같이 결정경계와 서포트 벡터 사이의 거리를 나타냅니다. (점선으로부터 실선까지의 거리, 실선은 점선으로부터 가장 가까운 데이터를 기준으로 생기게 됩니다.)
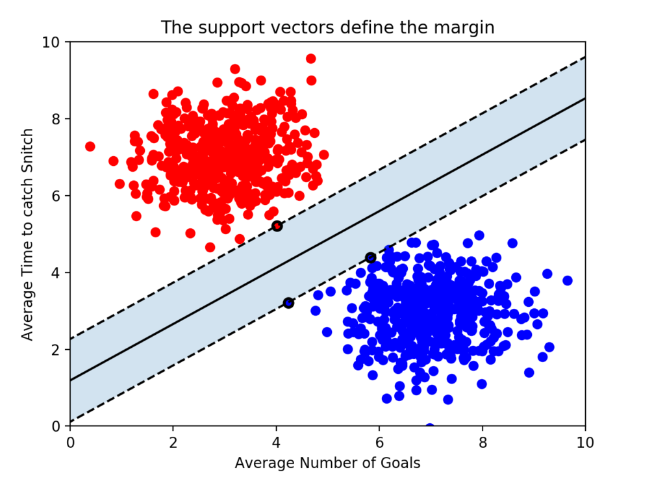
서포트 벡터(Support Vector)
서포트 벡터란 마진이 형성하는 결정경계와 가장 가까운 data를 말합니다. n개의 속성을 가진 데이터에는 최소 n+1개의 서포트 벡터가 존재합니다. SVM은 분류 실행 시에 서포트 벡터만 사용하기에(가장 가까운 점들만 사용하기에) train data가 많더라도 학습 속도가 빠릅니다.
- 하드마진(Hard Margin)
- 아웃라이어를 허용하지 않음.
- 서포트 벡터와 decision boundary 사이의 거리가 가깝다.
- 마진이 매우 작다.
- 오버피팅(overfitting) 문제 발생 가능
- 소프트 마진(Sof Margin)
- 아웃라이어들을 어느정도 허용
- 서포트 벡터와 decision boundary 사이의 거리가 멀다.
- 마진이 크다.
- 언더피팅(underfitting) 문제 발생 가능
'BOAZ > 데이터 분석' 카테고리의 다른 글
| 4. CNN (0) | 2022.08.18 |
|---|---|
| 3. Ensemble and Random Forest (0) | 2022.08.09 |
| [핸즈온 머신러닝] 3장 (0) | 2022.07.31 |
| 1. Classification and Regression (0) | 2022.07.28 |
| [핸즈온 머신러닝] 2장 머신러닝 프로젝트 처음부터 끝까지 (0) | 2022.07.27 |