본 논문에서 다루는 내용은 다음과 같습니다.
1. 많은 양의 데이터에서 퀄리티 높은 단어 벡터를 학습
2. 이전 모델 NNLM, RNNLM 소개
3. 새로운 모델 구조 CBOW, Skip-gram 제안
4. 모델 훈련 시간의 최소화, 정확도의 최대화
Introdution
Word2Vec 이전의 자연어 처리는 One-Hot encoding으로 표현하고 싶은 단어의 인덱스에 1을 부여하고 다른 인덱스에 0을 부여하는 형식으로 진행되었습니다. 하지만 이 방법은 단어 개수가 늘어나면 벡터 차원이 늘어난다는 점, sparse matrix, 단어 간 유사성을 계산할 수 없다는 한계들이 존재했습니다.

여기서 Distributed Representation(분산 표현)이란 방법을 사용할 경우 단어의 의미를 여러 차원에 분산해 표현하기 때문에 단어 벡터의 차원을 줄일 수 있고 단어의 유사도(similarity)를 측정할 수 있습니다.

- Knowledge Distilation에서도 Hard target(one-hot encoding)으로 표현하는 것보다 Soft-target이라는 방법을 사용하는데 이 경우 가장 확률이 높은 인덱스를 제외한 나머지 정보들도 얻을 수 있어 정보 손실을 줄일 수 있고, regularizaition 효과도 얻을 수 있기 때문에 one-hot encoding을 사용하지 않습니다.
간단하게 생각해보면 one-hot encoding을 할 경우 정보들이 버려지기 때문에 각각 단어들끼리 미세한 차이를 알 수 없다고 생각하시면 됩니다.
NNLM
NNLM: Neural Network Language Model은 정해진 앞 n개의 단어를 참고하여 다음 단어를 예측하는 모델입니다.

총 4개의 layer로 이루어진 신경망입니다. Input, Projection(Linear), Hidden(tanh), Output
𝑄 = (𝑁 × 𝐷) + (𝑁 × 𝐷 × 𝐻) + (𝐻 × 𝑉), computational complexity 계산 시
학습 과정은 다음과 같습니다.
1. One-Hot encoding으로 단어를 벡터로 변환
2. Lookup table: 입력과 가중치 행렬의 연산
3. Concatenate로 embedding word vector를 얻음
4. Hidden layer를 통해서 입력 벡터들과 동일한 차원의 벡터로 변환
5. Ouput layer에서 softmax를 통해 0~1 사이 실수 값으로 변환
NNLM의 장점은 단어 유사도 표현으로 희소 문제를 해결한다는 점과 N-gram 언어 모델보다 저차원이기 때문에 저장 공간을 적게 사용하는 점입니다.
단점으로는 정해진 n개의 단어만 사용한다는 것과 다양한 길이의 입력 시퀀스 처리가 어렵다는 점이 존재했기에 이 부분을 보안한 RNNLM이 등장하게 됩니다.
RNNLM
RNNLM: Recurrent Neural Network Language Model은 NNLM에 RNN(Time step) 개념을 도입하여 입력의 길이를 고정하지 않을 수 있도록 만든 모델입니다.
고정되지 않은 개수의 단어 입력이 가능하며 projection layer대신 Embedding layer을 사용합니다.
- Q = (H x H) + (H x V)
이전 시점의 출력을 현재 시점의 입력으로 사용하는데 한 번 잘못된 예측을 하면(이전 시점 출력이 잘못된 경우) 뒤에서의 예측에도 영향을 미쳐 훈련 시간이 느려지는 것을 방지하기 위해서 이전 시점의 정답값을 입력으로 사용합니다.
한계점으로는 이전 단어만 고려가 가능하고 계산 복잡도가 높다는 것입니다. 이러한 문제점을 해결한 것이 CBOW와 Skip-gram입니다.
Word2vec
Word2 vec에는 2가지 모델이 존재합니다. 주변 단어에서 중간 단어를 알아내는 CBOW와 중간 단어에서 주변 단어를 알아내는 Skip-gram
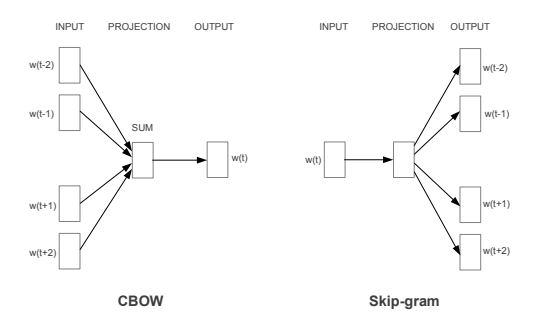
CBOW는 주변 단어로 중간에 있는 단어를 예측하는 방법입니다.
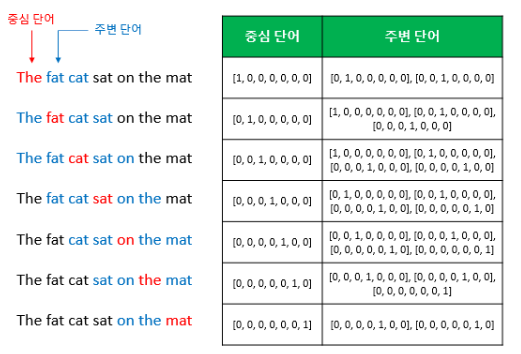
여기서 윈도우(window)라는 개념이 나오는데 중심 단어를 예측하기 위해 주변 단어 몇 개를 활용할지 정하는 범위라고 생각하시면 됩니다. 윈도우 크기가 n이라면 중심 단어 앞 n개, 뒤 n개로 총 2n개의 단어를 활용합니다.
훈련 복잡성은 Q = (N x D) + (D x log2(V))입니다.
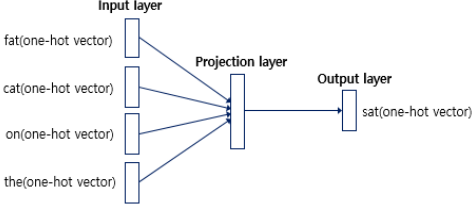
CBOW의 구조는 다음과 같이 사용자가 정한 윈도우 범위 안에 있는 주변 단어들을 one-hot vector로 입력하는 입력층과 Look up table 연산을 담당하는 은닉층 그리고 출력층이 존재합니다.
Skip-gram
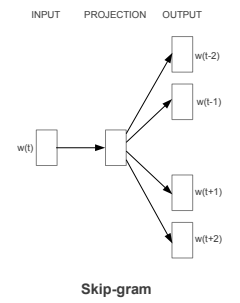
Skip-gram은 중심 단어를 단어 집합의 크기를 갖는 one-hot vector로 변환 후 입력하는 입력층과 input에 가중치 행렬 W를 곱해 N차원 임베딩 벡터를 얻고 임베딩 벡터에 2n개의 가중치 행렬을 곱하여 단어 집합의 크기와 같은 벡터를 얻는 은닉층 그리고 softmax로 확률로 해석할 수 있게 도와주는 출력층으로 구성되어 있습니다.
한계점
Word2vec의 한계점으로는 모든 단어를 각각의 vector로, 1:1로 representation 하는 것의 한계가 있습니다. training data에 등장하지 않은 rare word의 경우 정확한 vector embedding이 어렵습니다. 이를 OOV (Out of Vocabulary) 문제라고 합니다.
그다음으로는 단어의 형태학적 특성을 반영하지 못하는 한계점도 존재합니다. 유사한 의미의 개별적 단어가 문맥 정보를 기반으로 unique 하게 학습이 되는 문제가 존재하며 같은 의미의 여러 가지 형태의 단어를 모두 embedding 하기 어렵습니다.
Result
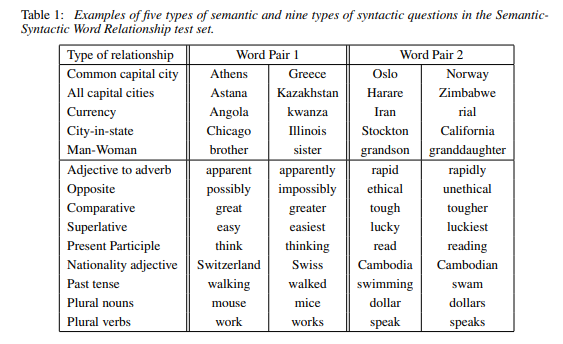
test set에 대한 Semantic(의미론적) question과 Syntactic(구문론적) question에 대한 내용입니다.
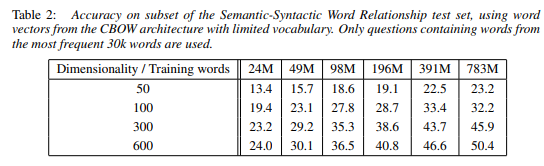
정확도를 최대화하기 위한 방법을 제시하는데 높은 성능을 위해서는 벡터 차원 (Dimensionality)과 훈련 데이터 (Training words)를 함께 늘려야 한다는 것을 알 수 있습니다.
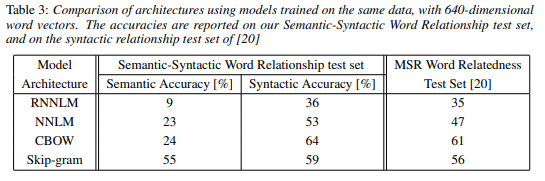
CBOW는 구문 작업에서 NNLM에 비해 성능이 향상되었으며 의미 작업에서는 성능이 유사합니다. Skip-gram은 CBOW 모델보다 구문 작업에서 성능이 저조하지만 의미 작업에서는 타 모델보다 우수하다는 것을 알 수 있습니다.
'논문 리뷰 > 여러가지 기법들' 카테고리의 다른 글
| Attention Is All You Need (0) | 2022.10.23 |
|---|---|
| Sequence to Sequence Learningwith Neural Networks (0) | 2022.09.18 |
| [논문 리뷰] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (0) | 2021.09.08 |