기존 Machine Translation 분야는 문장이 아닌 단어 단위의 번역에 그쳤기에 문장 구조나 문법을 고려하는 번역이 아닙니다. 고정된 길이의 input만 받는 DNN 역시 문장 길이에 맞게 유연하게 대처하지 못합니다. RNN 모델과 Seq2Seq와 같은 모델들은 단어와 이웃하는 단어 간의 관계를 고려하며 번역이 가능합니다.
- Sequence: 순서가 있는 data, Text에는 문맥이라는 순서가 있고 시계열 데이터에는 시간이라는 순서가 있습니다. 마찬가지로 영상, 음성 등 전부 순서와 함께 흘러가는 데이터입니다.
- Sequence model: Sequence data를 다루는 모델, 순서가 있는 Sequence data에서 특징들을 추출하여 여러 가지 문제를 해결하고 예측합니다. 대표적인 모델로는 RNN, LSTM, GRU가 존재합니다.
RNN

RNN 반복적이고 순차적인 데이터에 효과적인 모델입니다. 하지만 Vanishing Gradient 문제가 발생한다는 단점이 존재합니다. 앞의 정보를 뒤로 갈수록 충분히 전달되지 못하는 현상(Long-Term Dependency)이 있어 RNN은 짧은 시퀀스에서만 효과를 보입니다.
- Long Term Dependency (장기 의존성 문제) : 1보다 작은 값을 반복적으로 곱하는 수식이기 때문에 문장이 길 어질수록 앞의 정보를 뒤까지 전달하기 어려운 문제가 일어난다.
이러한 RNN의 한계점을 극복하기 위해서 첫 번째 RNN을 이용해서 입력에 대한 고정된 차원의 vector를 생성하고 두 번째 RNN에 해당하는 vector를 입력으로 제공해서 다른 sequence를 결과로 구하는 방법이 등장합니다.(LSTM)
LSTM
LSTM은 긴 문장에서도 좋은 성능을 냅니다. 가변 길이의 입력에 대해 고정된 길이의 벡터 표현이 가능합니다. 번역을 수행하기 위해서는 기존 문장을 paraphrasing을 하는 경향이 있다는 점을 감안하면 번역 목표는 LSTM이 그 의미를 내포하는 문장 표현들을 찾도록 하는 것입니다.(유사한 의미의 문장은 서로 가깝고, 다른 문장의 의미는 멀기 때문)
Seq2Seq
Encoder와 Decoder에 LSTM을 사용합니다. 입력을 순차적으로 받아서 큰 고정된 차원의 vector representation을 생성하고 그 vector로부터 output sequence를 추출합니다. (encoder - decoder 과정)

A, B, C 를 첫 번째 LSTM 모델에 입력합니다. 번역 결과인 w, x, y, z와 <EOS>가 두 번째 LSTM 모델을 통해 제공합니다. <EOS>는 문장의 끝을 구분하는 토큰 'end-of-sentence'입니다.

- Seq2Seq 모델은 크게 2개의 모듈 Encoder와 Decoder로 구성되어 있습니다.
- Encoder는 시계열 인풋 데이터를 압축해서 표현합니다.
- Decoder는 압축된 데이터를 시계열 아웃풋 데이터로 변환합니다.
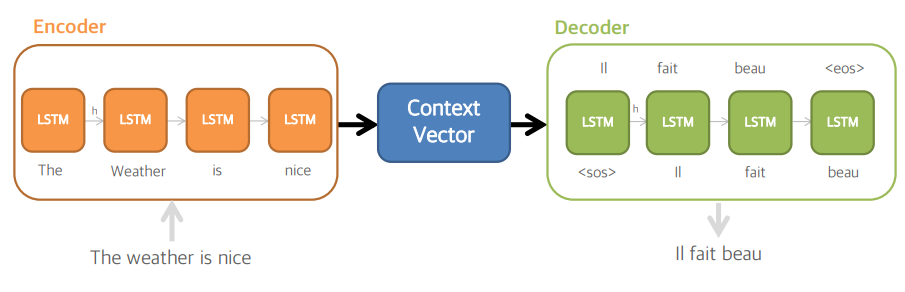
- 내부적으로 모듈은 LSTM 또는 GRU 셀(cell)로 구성
- 인코더와 디코더의 LSTM 셀은 약간 다름
- 두 종류 모두 결과로 hidden state (이후 h로 표현)을 출력한다.
- 입력 문장의 모든 단어들을 tokenization, word embedding을 거친 후 숫자로 변환되어 활용
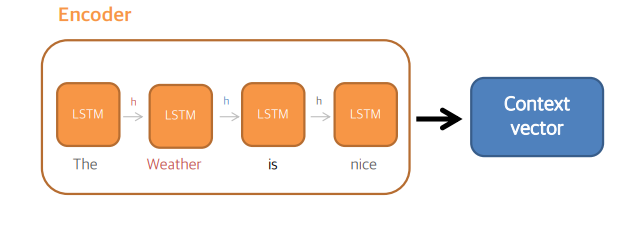
- Encoder의 각 셀은 입력 문장 단어와 직전 셀의 h를 받아서 h를 출력
- 예를 들어 두 번째 셀은 Weather과 직전 셀의 h를 활용해서 다음 셀로 넘겨질 h를 만들게 됨
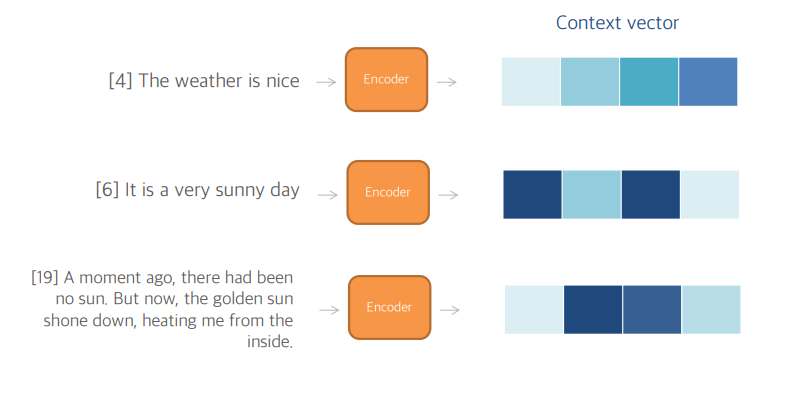
- 마지막 셀의 h는 Context vector라고 부르고 디코더에 쓰이게 됨
- Context vector은 입력 문장에 상관없이 길이가 고정되어 있음

- Decoder의 각 셀은 직전 셀이 예측한 단어와 h를 받아서 단어와 h를 출력
- 예를 들어 두 번째 셀은 직전 셀의 h와 ‘Il’라는 단어를 입력으로 받아 ‘fait’와 h를 출력
- Decoder의 첫 번째 셀은 토큰과 인코더의 아웃풋인 Context vector를 활용
- Testing의 경우 Decoder는 토큰이 나올 때까지 예측을 하게 됨
- Training의 경우 직전 셀이 예측한 단어가 아닌 true output을 입력으로 사용 (Teacher Forcing)
Training Details
1. 파라미터 초기화 값 : 모든 LSTM을 -0.08과 0.08 사이의 값으로 초기화
2. 각 단어 임베딩 차원 : 1000 차원
3. Optimizer : SGD (momentum 없이 사용)
4. Epoch : 7.5 epoch
5. Learning Rate : 3 epoch 까지 0.7로 고정, 이후에는 0.5 epoch 마다 ½로 줄임
6. Vanishing Gradient 문제를 최소화하기 위해 특정한 값을 정해서 해당 값을 벗어나는 경우 제어
7. Mini batch 내의 모든 문장들이 어느 정도 비슷한 길이가 되도록 제어
8. 총 8개의 GPU를 사용
Reversing the Source Sentences

- 반대로 입력하면 성능이 올라가는 현상을 발견 (BLEU score가 25.9에서 30.6까지 올라감)
- 순서를 뒤집으면 디코더의 첫 몇 단어가 인코더의 마지막 단어와 연관성이 높음
- 시간 종속성 문제가 감소해서 성능이 높아지는 것으로 분석
- LSTM은 직전 단어의 아웃풋과 예측 단어 영향을 많이 받기 때문에, 앞 단어 예측이 정확해질 수 록 모델 성능이 더 올라가는 모습을 보임
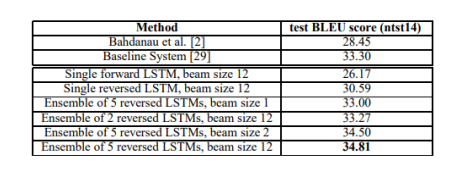
- Single LSTM을 활용했을 때 forward보다 reversed가 26에서 30으로 성능이 올라감
- 5개의 reversed LSTM을 앙상블한 결과 기존 baseline(Statistical Machine Translation)에 비해 33.30에서 34.81로 올라감
하지만 긴 문장의 경우 정보를 제대로 담지 못하는 문제가 존재, Encoder의 Context vector는 고정된 사이즈를 가지기 때문에 긴 문장의 경우 인코딩 과정에서 정보가 많이 손실된다.
Seq2Seq도 RNN만큼은 아니지만 time step을 따라 gradient update를 해야 하기 때문에 gradient vanishing 문제가 여전히 존재했다
정리
Seq2Seq 모델에서 새롭게 제안하는 3 가지
1. 인코더와 디코더에서 서로 다른 LSTM 구조를 활용해 RNN보다 우수한 성능을 보임
2. 4층으로 구성된 Deep LSTM을 활용
3. 입력 문장의 단어 순서를 뒤집어서 넣으면 성능이 올라가는 것을 발견 결과적으로 통계에 기반해서 예측하는 기계번역 SMT 기법을 뛰어넘는 성능을 보임
'논문 리뷰 > 여러가지 기법들' 카테고리의 다른 글
| Attention Is All You Need (0) | 2022.10.23 |
|---|---|
| Efficient Estimation Of Word Representations In Vector Space (0) | 2022.09.18 |
| [논문 리뷰] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (0) | 2021.09.08 |