본 논문에서 제안된 Transformer는 seq2seq의 구조인 인코더 디코더를 따르면서도 attention만으로 구현된 모델입니다. 기존 모델들은 정확도와 병렬화에 대해 문제가 존재했습니다.
1. 정확도
Sequential Model의 LSTM이나 GRU의 경우 번역 업무를 처리하기 위해 문장 전체를 하나의 벡터(Context vector)로 나타낼 필요가 있습니다. 이 경우 길이가 긴 문장의 경우 정해진 크기의 fixed vector로 줄어들기 때문에 정보 손실이 일어나게 되며 구조 상 뒤쪽의 정보가 아닌 앞쪽의 정보 대부분이 소실되어 문맥을 고려하지 못하는 경우가 많습니다.
2. 병렬화
번역 모델에서는 모두 이전의 셀에 대한 정보를 기반으로 현재의 셀을 업데이트하여 시간에 의존한 학습이 진행됩니다. 뒷쪽 셀 연산을 위해 그 이전까지의 셀 연산을 모두 해야 하지만 한 번에 여러 가지 일을 하는 것이 불가능해 비효율적입니다. CNN을 사용해 병렬화 문제를 해결할 수 있지만 종속성 문제를 해결하지는 못합니다.
이러한 기존 모델들의 문제점을 해결한 모델이 Transformer입니다. 트랜스포머는 시퀀스 정렬된 RNN이나 컨볼루션을 사용하지 않고도 입력과 출력의 표현까지 계산하기 위해 self-attention에 의존하는 최초의 변환 모델입니다.

Transformer 모델 구조

반복 또는 컨볼루션 신경망을 기반으로 하는 시퀀스 변환 모델을 self-attention 기반으로 대체합니다. 인코더와 디코더라는 단위가 N개로 구성되는 구조로 이 논문에서는 인코더 디코더를 각각 6개 사용합니다. input 이후 같은 architecture를 공유하는 6 Layer의 Encoder을 거친 후, 마지막 Encoder의 벡터들은 추후 디코더의 Cross-attention 시 사용해야 하므로 저장 후 뿌려줍니다.

Encoder
- 하이퍼 파라미터인 num_layers = 6개의 인코더 층을 쌓습니다.
- 하나의 인코더 층은 총 2개의 서브층으로 나뉘는데 첫 번째는 Multi-Head Attention 메커니즘, 두 번째는 Fully connected feed - forward 신경망입니다.
- 두 하위 계층 각각에 대한 residual connection을 사용하고, 그 다음에 계층 정규화를 진행합니다.
Decoder
- 디코더 또한 6개의 스택 층을 쌓습니다.
- 각 인코더 계층의 2개의 서브층 외에도 인코더 스택의 출력에 대해 Multi-Head Attention을 수행하는 제3 서브 계층을 삽입
- 인코더와 유사하게, 각 하위 계층에 대한 residual connection을 사용하고, 그 다음에 계층 정규화를 진행합니다.
Positional Encoding


트랜스포머 모델의 입력은 단어를 순차적으로 받는 방식이 아니기 때문에, 모델이 시퀀스의 순서를 이용하기 위해서 토큰의 상대적 또는 절대적 위치 정보를 주입해야 합니다. 첫 번째 사진에서 pos는 입력 문장에서의 임베딩 벡터의 위치를 나타내며, i는 임베딩 벡터 내의 차원의 인덱스를 의미합니다. 임베딩 벡터 내의 각 차원의 인덱스가 짝수인 경우에는 sin 함수의 값을 사용하고 홀수인 경우에는 cos 함수의 값을 사용합니다. 이렇게 positional encoding 방법을 사용하면 순서 정보가 보존됩니다.

Scaled Dot-Product Attention


어텐션 스코어에 소프트맥스 함수를 사용하여 어텐션 분포를 구하고 각 V벡터와 가중합을 하여 어텐션 값을 구합니다.
이 경우 최적화된 행렬 곱셈 코드를 사용하여 구현할 수 있기 때문에 매우 빠르고 공간 효율적입니다.
Multi-Head Attention
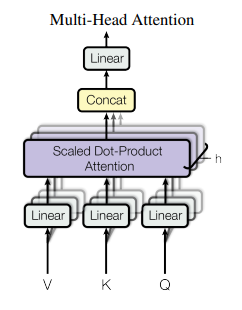
단일 attention을 수행하는 대신에 $d_k, d_v, d_q$ 차원에 쿼리, 키, 값의 h배를 선형적으로 투사하는 것이 더 효과적이라는 것을 발견하여 병렬로 실행되는 여러 Attention layer로 구성합니다.

Multi-Head Attention을 사용하는 이유는 Single Attention은 하나의 관점만 본다는 문제점이 존재했기 때문에 하나의 문장을 여러 가지 관점으로 본다기보다는 어떠한 하나의 관점을 기준으로 봅니다. 문장을 이해하기 위해서는 각 단어에 대해 문장의 관점을 달리 해야 하므로 Multi-Head Attention가 기존 Single Attention보다 효과적입니다.

