Six Steps in Execution of a Procedure

위 6단계는 프로세서에서 함수를 처리할 때 진행하는 동작으로 대부분의 프로세서가 이 6단계를 거칩니다. 첫 번째로 caller가 callee가 액세스 할 수 있는 곳에 argument를 가져다 둡니다. MIPS에서는 argument가 a0 ~ a3까지 4개의 레지스터를 통해 전달됩니다. 그다음 caller가 callee에게 control을 넘깁니다.
이제 callee가 실행되기 위해서 스택 공간에 메모리를 할당받습니다. 이후 callee가 일을 진행하고 끝나면 caller가 액세스할 수 있는 곳에 return value 값을 가져다 둡니다. MIPS에서는 v0 ~ v1으로 두 개의 value register를 사용합니다. 마지막으로 callee에서 caller로 control이 넘어가게 됩니다.
마지막 단계 이후에는 ra 레지스터에 담겨 있는 주소의 명령어 부터 실행하게 됩니다. (callee가 실행되기 전 그다음 PC 주소가 저장되어 있습니다.)
Procedure Call Instruction

Procedure call에 대해서는 위 2가지 명령어를 자주 사용합니다. jal은 jump and link 명령어로 jal 다음에 이동할 procedure label를 적어두면 해당 명령어도 이동하게 됩니다. 이동하기 전 다음 명령어의 주소(Program Counter)는 ra에 저장되게 됩니다.
Leaf Procedure Example

Leaf procedure란 하나의 함수에서 자기 자신이나 다른 함수를 부르지 않는 것을 말합니다. 이 함수에서는 파라미터가 4개 이기 때문에 argument register a0 ~ a3이 사용됩니다.

실제 위 코드의 어셈블리 코드입니다. stack pointer에 -4를 더하여 스택에 4byte 만큼의 메모리를 할당합니다. 그 이후 s0 레지스터 값을 현재 stack에 복사합니다. 그다음에 해당 함수에서 진행되는 산술 연산을 실행하고 결과를 v0로 복사합니다.
lw를 사용하여 스택에 보관되던 s0의 값을 다시 복원하고 stack pointer에 4를 더하여 스택 포인터 값을 다시 조정합니다. 이 과정은 이전에 할당했던 4byte 메모리를 해제시키는 과정입니다. 마지막으로 ra에 들어있던 caller의 주소로 이동하게 됩니다.
Non - Leaf Procedure Example

다른 함수들을 호출하는 경우 return address와 caller의 argument나 temporaries, pc 값을 stack으로 대피시켜야 합니다.

앞에 코드보다 더 복잡한 것을 볼 수 있습니다. 마찬가지로 스택에 8만큼의 공간을 만들고 ra, a0 레지스터의 값을 대피시킵니다. 이후 조건문에 대한 동작을 진행하고 더 진행할지 1을 반환할지 결정합니다.
Local Data on the Stack
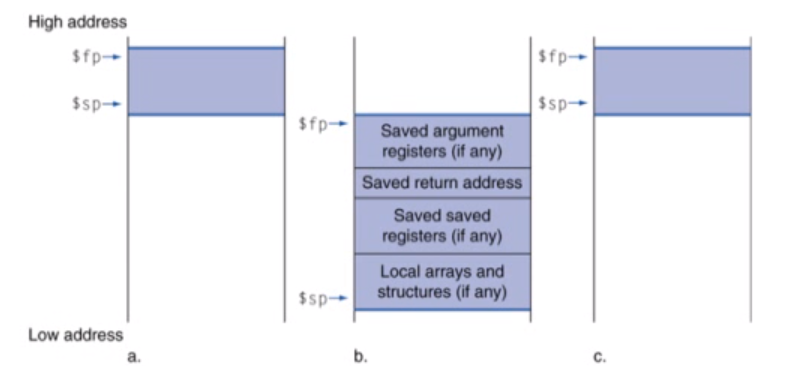
이번에는 frame pointer와 stack pointer에 대해서 배워보겠습니다. 함수에서 사용하는 지역변수(Local data)는 스택에 할당됩니다. sp는 현재 스택의 top 값을 가지고 있습니다. 우리가 함수를 실행하면 함수를 위해서 frame(activation record)이 만들어집니다. frame point는 이 frame의 시작 주소를 가리킵니다. 스택값은 sp가 가지고 있습니다.
Memory Layout

우리가 사용하는 프로그램의 메모리는 위 사진의 오른쪽과 같습니다. 제일 밑에는 reserved 그 위에는 text 영역으로 program code를 보관합니다. 그 위에는 global variable을 저장하는 static data 영역이 존재합니다. global pointer는 static data segment의 위치를 가르키고 있습니다. heap은 C에서 사용하는 malloc으로 영역을 할당할 때 사용되는 공간입니다. 그 윗부분이 stack 영역입니다.
- heap은 위로 메모리를 할당하고 stack은 아래로 메모리를 할당합니다.
Character Data

아스키 코드는 128개의 문자를 표현할 수 있고 Latin-1은 256개를 표현할 수 있습니다. 유니코드는 전 세계의 언어를 표현하고자 만든 것으로 보통 UTF-16을 많이 사용합니다.
Byte/Halfword Operations

lb는 load byte로 target register로부터 특정 부분 즉 1바이트를 읽고 sign 값을 rt에 저장합니다. lb는 unsign 값을 저장합니다. sb는 store byte이고 sh는 store half ward로 targe register에 하위 16bit를 저장합니다.
String Copy Example

두 어레이를 받아서 y arrary 값을 x arrary로 저장을 합니다. 이 함수는 leaf procedure로 볼 수 있습니다.
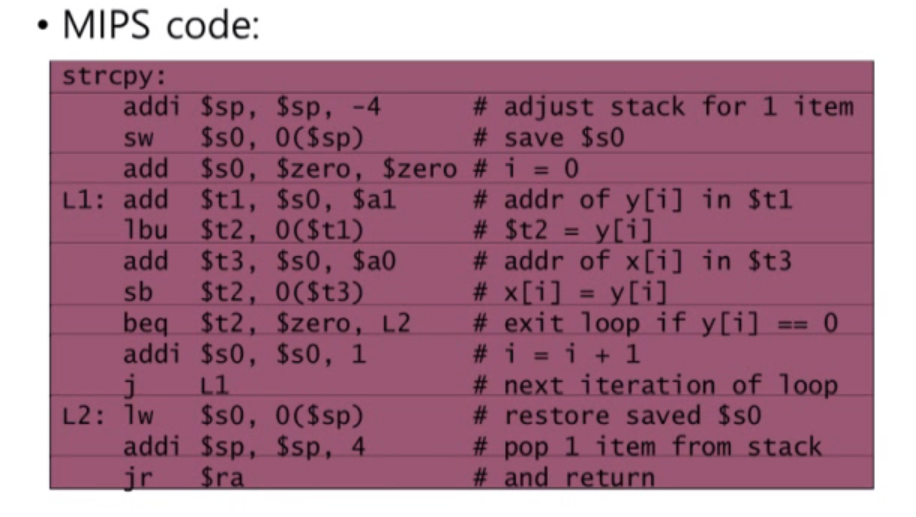
마찬가지로 스택 공간을 할당하여 s0 레지스터 값을 저장합니다.
32-bit Constans

프로그래밍을 할 때 32bit 상수를 만들어서 사용할 때가 있습니다. 대부분의 경우에 작은 상수값을 사용하여 16bit면 충분하지만 큰 상수를 쓸 때가 있습니다. 이때 사용하는 명령어가 lui(load upper)로 constant 값을 target register의 상위 16bit로 읽어오고 나머지 하위 16bit는 0으로 만듭니다. (lb 같은 경우 레지스터의 하위 32bit에 넣은 반면에 여기서는 상위 16bit에 넣습니다.)
그다음 ori를 통해 하위 16bit에 값을 넣는 형태로 동작합니다. 이렇게 16bit씩 2번 수정하면 32bit짜리 상수를 만들어서 사용할 수 있습니다. 이 방법 외에는 32bit 상수값을 저장하고 있는 레지스터에서 상수값을 읽어와야 합니다. 메모리를 액세스 하는 것보다 이렇게 2개의 레지스터 명령어를 사용하는 것이 훨씬 빠릅니다.
Addressing

branch 명령어는 다음과 같이 32bits 구조를 가집니다. opcode와 sourse register, target register, constant나 address를 가집니다. 대부분의 brach target은 branch 명령어 주변에 있습니다. 이런 방식의 addressing을 PC relative addressing이라고 부릅니다.
여기서 target address는 PC + offset * 4로 계산이 됩니다. 현재 프로그램 카운터에 하위 16bit와 4를 곱한 값을 더하는 방식으로 진행이 됩니다. (상대주소), 이때 프로그램 카운터는 현재 주소가 아닌 4만큼 증가된 주소를 가지고 있습니다. (프로그램 카운터는 현재 명령어를 실행할 때 미리 다음 명령어 주소를 가지고 있습니다.)

jump addressing은 두 영역으로 나눠지며 opcode를 제외한 나머지 하위 26bit가 전부 offset입니다. jump나 jump and link의 경우 text segment 어느 부분이든지 이동이 가능하여 명령어의 모든 address를 encoding 할 수 있습니다.
jump addressing에서 target address를 만드는 방법은 pc에서 상위 4bit을 가져오고 명령어에 존재하는 26bit에 4를 곱해서 더합니다. 이를 통해 32bit target address 값을 만듭니다.
Branching Far Away

Branch target이 너무 멀리 있어 offset으로 encoding 할 수 없는 경우 assembler가 원래 코드 beq를 bne와 j로 바꾸게 됩니다. jump의 경우 26bit을 사용하기에 16bit로 갈 수 없는 곳을 갈 수 있습니다.
Translation and Startup
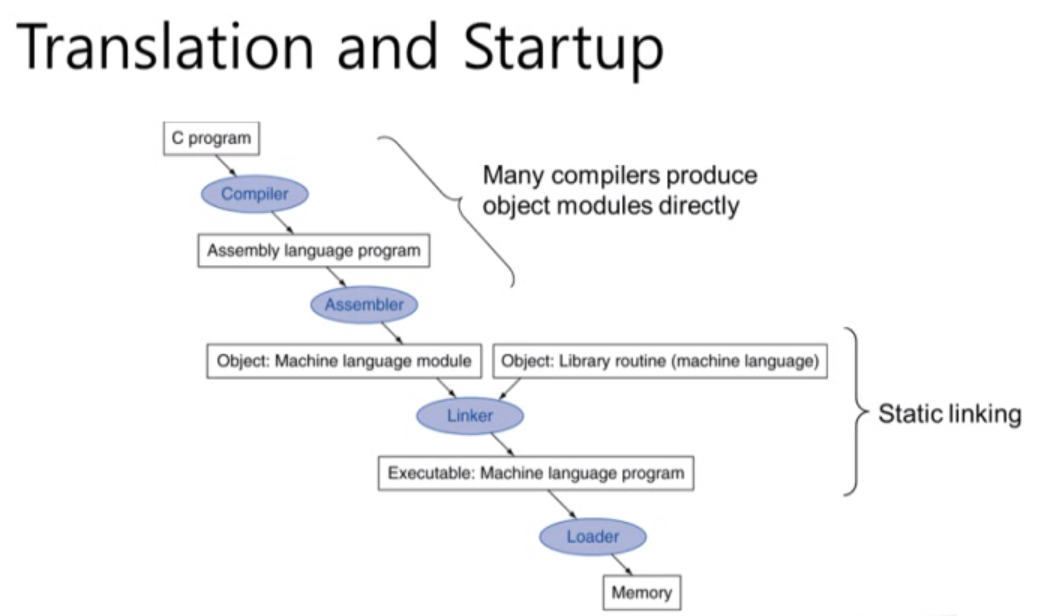
처음 C 프로그램을 작성한 뒤 컴파일 단계를 거칩니다. 컴파일을 통해서 assembly 프로그램으로 만듭니다. assembler는 이 프로그램을 다시 object 코드로 바꿉니다. 링커는 우리가 바꾼 오브젝트 파일과 필요한 라이브러리 오브젝트 파일을 묶어서 실행파일로 바꿉니다. 로더는 이 실행파일을 메모리에 올려서 실행시켜 줍니다.

실제로 프로세서에서 제공하지는 않지만 프로그램을 쉽게 하기 위해서 가상으로 제공하주는 명령어에 대해서 알아보겠습니다. 이런 가상의 명령어는 어셈블러가 실제 명령어로 변경해 줍니다. move의 경우 0을 더해 원하는 위치에 주고 blt의 경우에도 slt와 bne를 사용해서 진행합니다.
어셈블러는 코드를 기계 코드로 바꿉니다. 이런 코드 파일을 오브젝트 파일이라고 하는데 이 오브젝트 파일에는 header 정보와 text, static data 등의 실행할 때 필요한 정보들을 가지고 있습니다.
Linking Object Module

링커가 이런 오브젝트를 합치는데 우선 여러 개의 세그먼트를 합칩니다. 그 뒤 각각의 오브젝트 파일에서 사용하는 레이블들의 주소를 결정합니다. 마지막으로 location-dependent와 external refs를 맞춰줍니다. 프로그램은 버츄얼 메모리 상태에서 절대 주소를 값을 그냥 가지고 사용합니다. (알아서 동적으로 매핑을 진행)
만약 버츄얼 메모리를 지원하지 않는다면 relocating loader를 통해서 location-dependencies 값들을 전부 바꿔줘야 하지만 현대에는 MMU 하드웨어를 통해서 저절로 바뀌어집니다. 컴퓨터가 아닌 작은 디바이스에서는 MMU가 없어 버츄얼 메모리를 지원하지 않는 경우도 종종 존재합니다.
Loading a Program

프로그램을 로딩하는 과정에 대해 알아보겠습니다. header를 읽고 각각의 세그먼트의 크기와 종류를 알아냅니다. 그 이후 virtual address space를 만들고 text와 data를 memory로 복사하거나 페이지 테이블 엔트리만 세팅합니다. (page fault가 발생했을 때 데이터나 코드를 메모리로 올리기 위해서)
스택에 argument를 할당하고 레지스터를 초기화시킨 뒤 처음 시작하는 루틴으로 jump 하게 됩니다. C로 예를 들자면 main에서 사용하던 argument가 있다면 argument register로 값을 복사한 후 main을 부릅니다. main에서 끝나게 되면 syscall을 불러 종료됩니다.
Dynamic Lingking

다이내믹 링킹은 앞에서 배운 스태틱 링킹과는 반대되는 개념입니다. 복잡하기는 하지만 스태틱 링킹과 비교했을 때 장점이 많아서 현재에는 주로 사용되는 방식입니다. API나 라이브러리 함수를 만들어서 사용할 때 많이 사용합니다. 다이나믹 링킹은 실행할 때 링킹이 됩니다.
다이내믹 링킹을 사용하면 실제 이미지 크기가 커지지 않습니다. 그리고 새로운 라이브러리가 나왔을 때 스태틱 링킹의 경우 실행파일을 새로 만들었어야 하지만 다이나믹 링킹은 자동으로 새로운 라이브러리가 적용이 됩니다. 그리고 모든 라이브러리가 실행파일안에 들어가는 것이 아니라 다이나믹 링킹 라이브러리 파일에 따로 가지고 있습니다.
실행파일이 몇 개를 사용하던지 이미지의 크기가 커지지 않고 사용하는 함수를 부르는 procedure code만 필요합니다.
Lazy Lingkage

Lazy linkage의 경우 자주 사용하는 함수에 대해서는 data 부분에 미리 text 부분의 주소를 저장해 놔 바로 접근할 수 있습니다. 그래서 사진의 왼쪽 그림과 같이 순차적으로 접근하는 것이 아니라 바로 접근할 수 있게 됩니다. (캐시 같은 역할), data 부분의 indirect table에 시작 주소를 적어둡니다.
static linking의 경우 어떤 함수로 가기 위해서는 jump나 branch를 1번 사용하지만 dynamic linking은 indirect table을 거쳐서 갑니다. 첫 번째 실행인 경우 훨씬 더 복잡한 경로를 거칩니다. static linking에 비해서 느리다는 단점이 존재하지만 새로운 버전을 업데이트할 필요가 없다는 점에서 더 많이 사용됩니다.
'CS > Computer Architecture' 카테고리의 다른 글
| 6. Arithmetic for Computer (0) | 2024.02.19 |
|---|---|
| 5. Instructions (0) | 2024.02.18 |
| 3. Instructions: Language of the Computer (1) | 2024.02.06 |
| 2. The Power wall (0) | 2024.02.06 |
| 1. Performance (2) | 2024.02.05 |