
위 코드는 bubble sort c코드입니다. 이 코드를 어셈블리어로 바꿔보겠습니다. 각각의 변수들을 위 사진과 같은 레지스터에 매핑했을 때 아래와 같은 코드가 나오게 됩니다.

integer array 이까 개수만큼 k를 곱하여 어레이를 만들고 v와 더해 t1 레지스터에 넣습니다. 이러면 v [k] 어레이의 시작 주소가 t1 레지스터가 됩니다. 이후 v [k+1] 값을 t2에 넣습니다. 다음으로는 Non-leaf 예제에 대해서 알아보겠습니다.

bubble sort는 기본적으로 2개의 loop가 필요합니다. 이 경우에는 코드가 길어집니다.
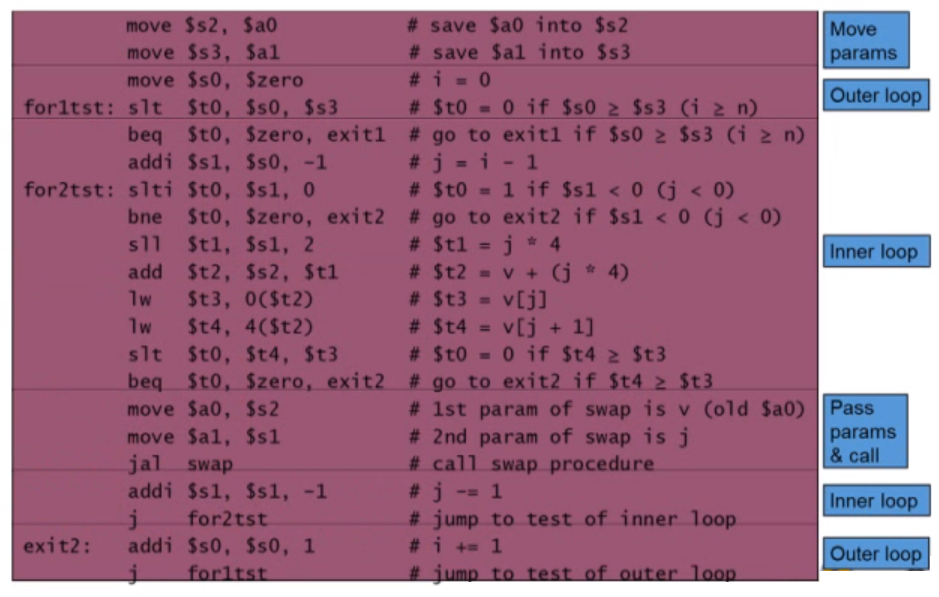
inner loop와 outer loop 2개가 존재하며 아래에서 5번째 줄에서 swap function을 부르는 것을 볼 수 있습니다.
Effect of Compiler Optimization

위 사진은 Pentium 4 Linux 환경에서 컴파일러 optimization을 적용한 모습을 보여주는 그래프 입니다. O1~O3까지 존재하는데 O3로 갈수록 더 많은 optimizatino을 적용한 것입니다. Relative Performance를 보면 최적화를 적용했을 때 성능차이가 두드러지지만 O1에서 더 진행하더라도 큰 차이가 나지 않습니다.
Clock cycle과 instruction count는 반비례 관계입니다. Instruction count는 O1에 비해서 O3가 더 높습니다. 그렇지만 O3가 O1보다 CPI가 높아 성능이 더 좋습니다.
Lessons Learnt

위에서 비교를 할 때 instruction count와 CPI를 사용했었는데 이 두 지표는 좋은 성능지표가 아니기 때문에 종합적으로 봐야됩니다. 컴파일러 최적화는 알고리즘과 관련이 많습니다.
Arrays and Pointers

프로그래밍을 할 때 array를 사용할 수도 있고 pointer를 사용할 수도 있습니다. array의 경우 기본적으로 index를 사용하며 어셈블리어의 동작을 봤을 때 index에 element size를 곱해 base address에 더해수는 역할을 합니다. ponter의 경우 메모리 주소값을 사용하기 때문에 array와 달리 indexing을 하지 않아도 됩니다.

위 프로그램은 array를 초기화하는 동작을 진행하는데 왼쪽의 경우 array 방식이고 오른쪽은 pointer 방식입니다. array 방식은 인덱스를 사용하여 초기화하고 포인터는 array의 시작주소 값에 4를 더해 다음 원소를 찾습니다. array는 매 루프마다 인덱스에 4를 곱해서 base address에 대해주는 작업을 진행하기에 포인터 방식보다 더 많은 명령어를 사용합니다.

그래서 multiply 방식 대신에 더 빠른 shift를 사용하는데, 최신 컴파일러들은 전문적인 프로그래머가 포인터를 사용하여 작성한 프로그램만큼 array로 작성된 코드도 빠릅니다. (array를 사용하더라도 pointer와 같은 효과를 얻으니 프로그램을 이해하기 쉽고 구현이 더 편한 array 방식으로 진행하자)
ARM & MIPS Similarities
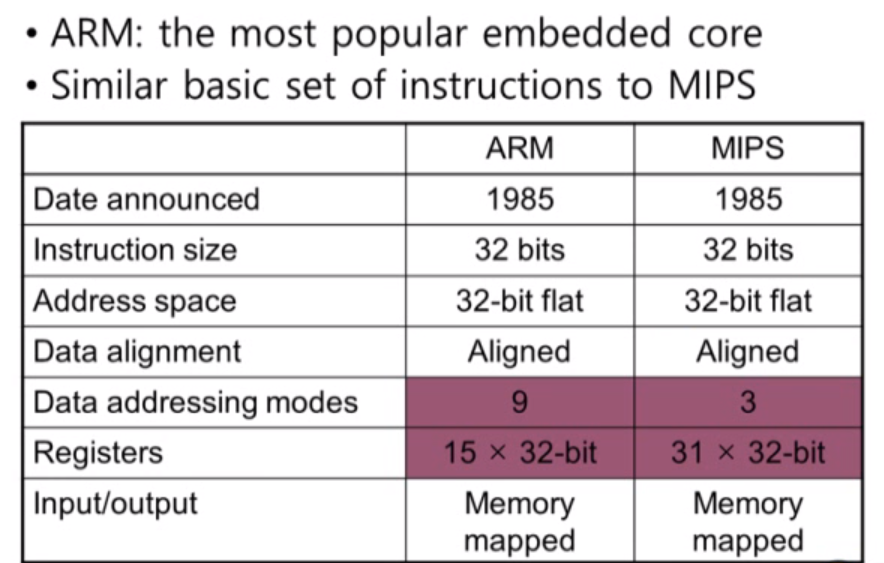
ARM과 MIPS는 유사한 부분이 많습니다. ARM은 현재 임베디드 시스템에서 가장 많이 사용하는 프로세서 입니다. 그래서 MIPS의 특성들이 ARM에 대부분 적용됩니다.

ARM 프로그램의 가장 큰 특징은 conditional execution 입니다. MIPS에는 지원되지 않는 기능으로 arithmemic / logical instruction을 사용했을 때 그 결과에 조건을 걸어줄 수 있습니다. 이 조건에 따라 뒤에 명령어를 실행하거나 무시할 수 있는 기능을 제공할 수 있습니다.
명령어의 상위 4bits가 conditional value로 이 bits을 통해서 branch 명령어 없이 branch 기능을 구현할 수 있습니다. 명령어들을 더 간소화한 것입니다.
현재까지 인텔이 많이 사용이 되는데 인텔의 경우 성능이 다른 프로세서에 비해서 뛰어나지 않지만 호환성을 계속 제공해주기 때문에 기존 프로그램이 실행이 가능하여 아직까지 표준으로 사용이 됩니다.

이 레지스터가 인텔 레지스터의 형태인데 MIPS와의 가장 큰 차이점은 MIPS는 모든 레지스터의 길이가 32bits인데 반해 인텔은 16 bits, 32 bits 등 각각 다릅니다.

인텔의 가장 큰 차이점은 일반적인 명령어에서 메모리 어드레싱이 가능합니다. 명령어에는 두 개의 오퍼랜드가 존재하는데 MIPS와 달리 레지스터와 메모리, 메모리와 레지스터, 메모리와 immediate 이렇게 3가지 방식을 지원합니다. (MIPS는 load store 명령어를 통해서 메모리 액세스가 가능)
다양한 기능을 제공하기에 구현이 아주 까다롭습니다. 그래서 MIPS는 RISC라고 부르지만 인텔은 CISC로 부릅니다. 구현이 까다롭고 복잡하기에 고성능으로 만들기가 어렵습니다. 인텔을 microperation이라는 방법을 사용하여 성능을 높였습니다. 이 방법은 소프트웨어가 아니라 하드웨어가 복잡한 명령어를 간단한 명령어로 쪼갭니다.
이렇게 나눠진 microoperation을 micorengine에서 실행합니다. micorengine은 RISC와 유사하게 볼 수 있기 때문에 인텔도 내부적으로는 RISC를 사용한다고 볼 수 있습니다. 이를 통해서 예전 기능을 호환시켜주면서 성능은 높일 수 있습니다. 하지만 translation 해주는 추가적인 작업이 필요합니다.
이 방식을 통해서 CISC 임에도 불구하고 RISC와 비슷한 성능을 낼 수 있었습니다. 그래서 컴파일러 또한 가능하면 복잡한 명령어를 사용하지 않습니다. (간단한 명령어로 실행할 수 있게 바꿔줌)
Fallacies

Powerful instruction은 CISC에 있던 복잡한 명령어를 의미합니다. 과거에는 여러 개의 일을 한꺼번에 처리할 수 있어 높은 성능을 낼 것이라 예상했지만 복잡한 명령어는 구현하기 어렵기 때문에 하드웨어에서 gate의 수가 많아집니다. 이렇게 되면 clock이 느려지게 되고 모든 명령어들이 느린 clock으로 동작하게 됩니다. (빠른 clock으로 실행되는 명령어 또한)
그래서 컴파일러가 간단한 명령어를 여러 개를 사용하는 것이 오히려 효율적일 수 있습니다. 간단한 명령어로 복잡한 명령어와 같은 동작을 하면 clock 속도를 높여 성능을 높이는 접근이 RISC의 목적입니다. 어셈블리어로 코드를 작성하면 코드 길이를 줄여 높은 성능을 낼 수 있지만 최신 컴파일러가 비슷한 성능을 낼 수 있게 도와주기 때문에 굳이 어셈블리어로 작성하지 않아도 됩니다.

인텔이 지원하는 명령어는 수는 시간이 지남에 따라 계속 증가합니다. 예전에 지원했던 명령어도 지원하기 때문에 backward compatiblity는 보장이 됩니다.
'CS > Computer Architecture' 카테고리의 다른 글
| 6. Arithmetic for Computer (0) | 2024.02.19 |
|---|---|
| 4. Instructions (0) | 2024.02.13 |
| 3. Instructions: Language of the Computer (1) | 2024.02.06 |
| 2. The Power wall (0) | 2024.02.06 |
| 1. Performance (2) | 2024.02.05 |