컴퓨터 기술을 빠르게 발전하고 있는데 그 원동력은 무어의 법칙으로 설명이 가능합니다. 무어의 법칙은 특정한 싱글 칩에 들어가는 트랜지스터의 수가 매 2년마다 2배씩 증가한다는 법칙입니다. (실제로는 2배보다 더 크게 증가했습니다, 로그 스케일 함수처럼 증가)
과거에는 많은 연산량을 가진 문제들에 대해서는 해결하지 못했지만 컴퓨터 성능이 발전하면서 새로운 애플리케이션들이 등장하고 있습니다.
컴퓨터는 크게 2가지로 나눌 수 있습니다. 첫 번째가 개인용 컴퓨터(Personal computer)로 가격 대비 성능에 민감하다는 특징이 존재하고 두 번째가 서버 컴퓨터(Server computer)로 고가에 대용량이며 고성능입니다. 최근에는 임베디드 컴퓨터(Embedded computer)들이 많이 보급되고 있습니다.
- 임베디드 컴퓨터는 어떤 제품, 시스템에 구성요소(compoents)로 내장된 컴퓨터를 말합니다.
- 앞서 말한 컴퓨터들과 다르게 전력 소모도 적고 유지비용도 적다는 장점이 있습니다.
- 스마트폰 태블릿 등등에 사용됩니다.
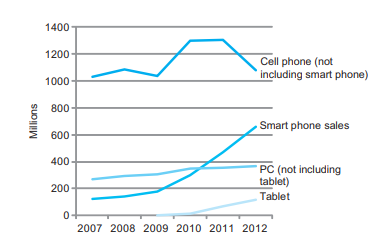
2007~2012년도 사이 제품 판매량을 본다면 기존 pc보다 태블릿이나 스마트폰 같은 임베디드 컴퓨터가 더 잘 팔립니다.
현재에는 직접 서버를 만드는 것보다 클라우드 컴퓨터를 통해서 특정 데이터를 처리하는 서버를 제공받는 경우가 많아지고 있습니다. 필요한 만큼 서버를 할당받아 사용할 수 있기 때문입니다.
스마트폰으로 설명해보자면 사용하는 소프트웨어 일부분은 PMD에서 실행되고 나머지 중요한 부분이나 복잡한 연산들은 클라우드에서 실행되는 형태입니다.
알고리즘(Algorithm)에서 성능은 operation의 수로 정의가 됩니다.(operation이 많을수록 더 오래 걸림), 같은 일을 하는 두 가지 알고리즘이 있을 때 operation의 수가 적으면 성능이 더 좋습니다.
- program language, compiler, architecture에서는 instruction의 수로 정의가 됩니다.
- 프로세스와 메모리에서는 단위 시간당 얼마나 많은 명령을 실행하는가로 결정이 됩니다.
- I/O에서는 input/output의 operation 수로 결정이 됩니다.(단위 시간당 얼마나 많은 operation을 실행하는가)
성능 향상을 위한 아이디어(Eight Great Ideas)
1. Design for Moore's Law
2. Use abstraction to simplify design: 단순화
3. Make the common case fast: 아주 많이 사용하는 일반적인 것을 빠르게 처리
4. Performance via parallelism: 병렬처리로 성능 향상
5. Performance via pipelining: 파이프 라인을 통한 성능 향상
6. Performance via prediction: 예측을 통한 성능 향상
7. Hierarchy of memories: 메모리 구조
8. Dependability via redundancy: Redundancy를 이용한 신뢰성 향상(RAID)
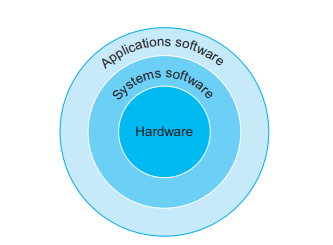
프로그램에 대해서 더 배워보겠습니다. 프로그램 중 일반적인 유저가 사용하는 애플리케이션 소프트웨어가 존재합니다. 그리고 OS나 컴파일러라는 기본적인 시스템 소프트웨어가 존재합니다. 컴파일러는 하이레벨 코드를 머신 코드로 바꿔주고 OS는 애플리케이션에 메모리 관리, input/output 관리, scheduling 등 서비스를 제공해 줍니다.
- 하드웨어는 실제로 만질 수 있는 물리적인 부분입니다.

이 사진은 컴퓨터 내부를 알아보기 쉽게 보여주고 있습니다. desktop, server, embedded 등 많은 컴퓨터들이 비슷한 구성요소를 가집니다. I/O 디바이스를 가지거나 데이터를 저장하기 위한 하드 디스크 같은 디바이스 등을 가집니다.
CPU
프로세서 내부를 봐보겠습니다. cpu는 3가지 구성요소로 되어있는데
1. Datapath: 데이터가 어떻게 연산되는지, 연산에 관한 모든 것들
2. Control: 컴퓨터에 있는 모든 장치들의 동작을 지시하고 제어하는 장치입니다.
3. Cache memory: CPU 내부에 아주 빠른 SRAM을 가지고 있는데 이것이 Cache memory입니다.
- 자주 사용하는 데이터를 올려나서 빠르게 연산
- CPU에서 실절적인 연산 장소는 core입니다.
Abstraction
이번에는 추상화(Abstraction)에 대해서 알아보겠습니다.
복잡한 자료나 모듈 시스템 등으로부터 핵심적인 개념이나 기능을 추출한다면 (추상화) 효과적일 것입니다.
- 복잡한 문제를 단순화하여 쉽게 풀 수 있게 하는 것
컴퓨터에서는 ISA(Instraction Set Architecture)라는 추상화의 대표적인 예시가 있습니다. ISA는 하드웨어 소프트웨어 인터페이스입니다. 소프트웨어는 instruction으로 구성되어 있고 하드웨어는 이 instruction을 실행합니다. 하드웨어랑 소프트웨어는 instruction을 통해서 데이터를 주고받습니다.
이 instruction은 0과 1로 이루어진 bit stream으로 CPU가 실행하게 됩니다. 이때 CPU 마다 자기가 실행 가능한 instruction을 묶어두는데 이걸 Instruction Set이라고 부릅니다. instruction은 add, sub, compare, jump, load, store 등의 다양한 연산들로 구성되어 있습니다.

다시 ISA로 돌아와서 조금 더 자세히 알아본다면 ISA는 프로그래머에게 보이는 컴퓨터 구조입니다. 메모리를 가지고 있다면 어디까지 접근이 가능한지, 레지스터는 몇 개나 가지고 있는지 이런 정보를 보여주는 겁니다. ISA를 하드웨어(CPU)와 소프트웨어의 인터페이스라고 말했는데 이는 ISA가 CPU가 어떤 명령어를 이해하는지, 메모리와 레지스터를 어떻게 사용할 수 있는지 정의합니다.
- 어떻게 보면 응용 프로그램과 하드웨어의 인터페이스 역할을 하는 OS와 비슷하다고 볼 수 있습니다.
- 다만 차이점은 ISA는 CPU 수준에서 소프트웨어와 하드웨어의 인터페이스 역할을 합니다.
- ISA는 CPU가 이해할 수 있는 명령어를 제공하는데 초점이 맞춰져 있습니다. (OS가 CPU를 사용하는 걸 도움)
- OS는 CPU, 메모리, I/O 디바이스 등 모든 하드웨어 자원을 관리합니다.
ISA는 하드웨어마다 다양하게 존재하는데 대표적으로 MIPS와 같이 간단한 구조부터 복잡한 구조를 가진 Intel의 ISA가 존재합니다. Intel의 ISA는 굉장히 많은 Instruction을 제공하여 MIPS와 비교했을 때 비교적 짧게 코드 작성이 가능합니다. 하지만 굉장히 많은 instruction을 실행하는 하드웨어를 가지게 되면서 internal operation, 하드웨어 버그 등으로 문제가 발생했을 때 소프트웨어 개발자가 할 수 있는 일이 없습니다.
- 복잡한 하드웨어이면 다양한 부분에서 고장이나 소프트웨어 개발자가 할 수 있는 게 없음

그래서 The case for the reduced instruction set computer 논문에서는 비슷한 성능을 낼 수 있도록 하드웨어를 단순화하고 병렬 처리를 통해서 훨씬 빠르게 실행하는 것이 유리하다고 말합니다. 또한 VAX 등의 복잡한 Instriction set을 가지는 경우 복잡한 명령을 하드웨어로 구현하기 때문에 제거할 수 없는 추가적인 작업이 발생하여 오히려 소프트웨어로 구현한 것보다 못한 성능을 낼 수 있습니다.
Application Binary Interface(ABI)라는 개념도 존재하는데 이건 ISA와 system software interface를 합쳐서 부르는 말입니다. 이 ABI는 한 컴퓨터 시스템에 있는 프로그램이 다른 컴퓨터 시스템에서 실행이 되는지 알려주는 조건입니다. (ABI가 같은 컴퓨터의 경우 프로그램을 돌려 쓸 수 있습니다.)
프로그램 중 일반적인 유저가 사용하는 애플리케이션 소프트웨어가 존재합니다. 그리고 OS나 컴파일러라는 기본적인 시스템 소프트웨어가 존재합니다. 컴파일러는 하이레벨 코드를 머신 코드로 바꿔주고 OS는 애플리케이션에 메모리 관리, input/output 관리, scheduling 등 서비스를 제공해 줍니다.
A Safe Place for Data
메인 메모리로 사용하는 DRAM은 휘발성(volatile memory)으로 전원이 나가면 사라집니다. 저장 장치에서는 휘발성이 있으면 안 되는 Magnetic disk, Flash memory, Optical disk 등등을 사용합니다. 이 저장 장치는 스토리지나 보조기억장치(secondary memory)라고 부릅니다.
Networks
컴퓨터는 입력, 계산, 저장하며 네트워크를 연결하여 communication, resource sharing, nonlocal access와 같은 이점을 얻을 수 있습니다.
네트워크의 종류는 다음과 같습니다.
- LAN(Local Area Network): 근거리 네트워크로 넓은 범위에서 사용할 수는 없지만 소규모 공간 안에 고속 통신회선이 가능합니다. WAN보다 빠른 통신속도를 가지면 보통 Peer - to - Peer 형태입니다.
- WAN(Wide Area Network): 광대역 네트워크 망으로 LAN과 LAN을 다시 하나로 묶은 것으로 소규모 LAN들을 묶어 서로 다른 지역에서도 통신할 수 있게 만든 것입니다.
- Wireless network: WiFi, Bluetooth
Technology Trend
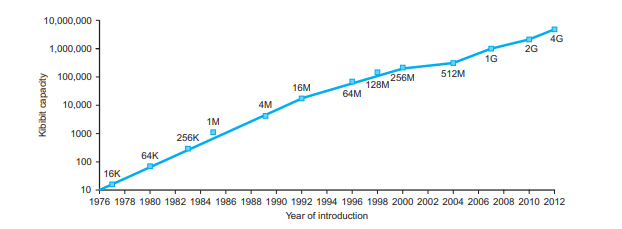
시간이 지남에 따른 DRAM chip 용량 증가 그래프입니다. capacity를 보면 2년 ~ 3년마다 2배 가까이 증가하는 것을 알 수 있습니다. chip을 만든다는 것은 실제 실리콘에다 기판을 새겨 넣는 것입니다. 이런 작업을 통해서 Conductors, Insulators, Switch와 같은 동작을 하게 만들 수 있습니다.
공정에서 Yield라는 단어를 사용하는데 이것은 웨이퍼 당 die의 proportion입니다. 즉 하나의 웨이퍼에 몇 개의 die가 성공적으로 들어갔냐를 의미합니다. 계산하는 방법은 다음과 같습니다.
$Yiled = \frac 1 {(1 + (Defects per area \times Die area / 2))^2}$

위 사진을 통해서 칩의 밀도(Normalized transistor)는 계속 증가하지만 Clock speed는 평평한 것을 알 수 있습니다. 전력 밀도 때문에 생긴 문제입니다.

위 사진은 전력 밀도의 성장을 보여주는 인텔의 슬라이드입니다. 칩에 있는 트랜지스터를 기존과 같은 방식으로 계속 확장하면 2010년에는 태양 표면의 온도와 같아질 것이라고 판단했습니다. 전력누설이나 회로에서 정전기가 새는 문제가 발생하기 때문입니다. 왜 그럴까요?
동적 전력 소비는 다음과 같습니다.
$$P = C \times V^2 \times f$$
V는 전압 f는 주파수 입니다. 여기서 프로세서의 속도를 높이기 위해서 f를 높이게 되면 동적 전력 소비가 높아지게 됩니다. 그래서 주파수를 높이면서 전압을 낮추는데 전압을 낮추면 정적 전력 소비(누설)가 높아지게 되는 문제가 생깁니다.
Defububg Performance
성능이 좋다는 것은 무엇을 의미할까요? 여객기를 통해 예시를 들어보겠습니다.

여기 여러 여객기의 탑승 인원, 비행거리, 속도. 단위 시간당 수송 가능한 승객 수를 알 수 있는 표가 있습니다. 이 표를 통해서 우리는
- Concorde가 속도가 가장 빠르다.
- DC-8이 비행거리가 가장 길다.
- Boeing 747이 수송 인원이 가장 많다.
등등의 정보를 얻을 수 있습니다. 어떤 여객기가 가장 성능이 좋은지 알아보기 위해서는 우선 성능의 정의를 정해야 합니다. 가장 많은 승객을 다른 장소로 이동시키는 것을 성능으로 정의한다면 승객 처리량이 가장 큰 747의 성능이 가장 좋다고 할 수 있을 것입니다. 하지만 목적지에 도착하는 시간을 성능의 기준으로 정한다면 성능이 가장 좋은 여객기는 달라집니다.
컴퓨터의 성능은 어떻게 정의될까요?
- Response time / Latency(응답 시간): 어떤 operation을 할 때 얼마나 걸리나(하나의 operation에 걸리는 시간이 respone time)
- Throughput(처리량): 단위 시간당 얼마나 많은 일을 할 수 있는가 (한 시간에 실행한 task의 수)
원래 사용하던 CPU보다 더 좋은 성능의 CPU를 사용한다면 Response time과 Throughput 둘 다 영향을 받습니다. Response time이 감소하게 되면 operation을 더 빨리 처리하니 Throughput도 증가합니다. 하지만 더 좋은 CPU를 사용하는 것이 아닌 원래 CPU를 병렬로 연결한다면 Response time은 변하지 않습니다. 하지만 operation을 처리해 주는 친구가 한 명 더 늘어나서 Throughput은 증가합니다.
- 일반적으로 Response time을 줄이면 Throughput도 증가합니다. (Response time은 Throughput에 영향을 줌)
- 반대로 Throughput이 증가하더라도 Response time에 영향을 주지 못하는 경우가 있습니다.
여기서 성능은 Response time을 기준으로 설정하여 진행할 것입니다.
Response time은 execution time(실행시간)이라고 할 수 있습니다. 성능과 실행시간의 관계는 역수 관계로 실행시간이 더 적을수록 좋은 성능을 보입니다. 실행시간이 각각 10초와 15초 간의 성능은 1.5배 차이입니다.
$$ Performance = \frac {1}{Execution time} $$
$$\frac {Performance_x} {Performance_y} = \frac {Execution time_y}{Execution time_x} = n$$
이 밖에도 Elapsed time(걸린 시간) 어떤 operation이 실행되면서 걸린 모든 시간을 의미합니다. response time은 cpu에 대한 operation 실행 시간이고 elapsed time은 I/O나 다른 소프트웨어 시간까지 합친 것입니다. 시스템 퍼포먼스를 정의할 때 사용합니다.
그리고 CPU time은 어떤 일을 할 때 cpu에서만 걸린 시간을 의미합니다. 이 cpu time은 user cpu time과 system cpu time으로 나눠집니다. 각각 user level에서 걸린 시간과 OS에서 걸린 시간을 포함하는 것을 의미합니다.(cpu나 시스템 퍼포먼스에 영향을 받음)
CPU Clocking

clock rising edge에서 다음 clock rising edge까지 걸리는 기간을 clock period라고 합니다. 즉 하나의 clock cycle 동안 걸린 시간을 의미합니다. clock rate( frequnecy )는 초당 몇 clock cycle이 있는지를 의미합니다. 단위는 Hz를 사용합니다.
- Cycle period: 250ps = 0.25ns = $250 \times 10^{-12} s$, 단위는 시간 단위입니다.
Clock frequency와 Clock period는 반비례 관계입니다.(진동 수와 주기는 반비례)
$Clock\,period = \frac 1 {Clock\,rate} $
CPU Time
CPU time은 아래와 같이 계산됩니다.
$$CPU \, Time = CPU \, Clock\, Cycles \times CPU \, Time \, Time = \frac { CPU \, Clock\, Cycles } {Clock \, Rate}$$
이렇게 되는 이유가 clock period는 clock rate의 역수가 되기 때문에 위와 같이 변형을 할 수 있습니다. 이 수식을 통해서 알 수 있는 점은 CPU time을 줄이기 위해서는 number of clock cycles을 줄이면서 clock rate를 높이면 됩니다. (또는 clock period를 낮추면 됩니다.)
하지만 하드웨어 설계 단계에서 clock rate를 높이면 number of clock cycle이 증가하는 trade off가 발생합니다. 즉 이 비율을 잘 조정해서 성능이 가장 높은 비율을 찾아야 합니다.
Instruction Count and CPI
위에서 number of clock cycles는 다음과 같습니다.
$$Instruction \,count \times Cycles\, per\, Instruction$$
여기서 Cycles per Instruction이 CPI입니다. 명령어를 실행시키는데 몇 사이클이 걸리냐를 나타내주는 척도입니다. 즉 실행되는 명령어 개수와 명령어를 실행시키는데 걸리는 사이클 수를 곱하면 모든 instruction을 실행하는데 필요한 cycle의 수를 구할 수 있습니다.
instruction count는 프로그램(소스 코드의 길이, 자체 알고리즘), ISA, compiler에 의해서 결정됩니다. 프로그램은 하나의 명령어가 아닌 여러 개의 명령어로 구성되어 있습니다. 그렇기 때문에 average cycle per instruction을 구해서 CPI 부분에 넣어 사용하는 게 더 정확합니다. (Average CPI의 경우 프로그램마다 구성되는 instruction의 차이로 다 다릅니다.)
'CS > Computer Architecture' 카테고리의 다른 글
| 6. Arithmetic for Computer (0) | 2024.02.19 |
|---|---|
| 5. Instructions (0) | 2024.02.18 |
| 4. Instructions (0) | 2024.02.13 |
| 3. Instructions: Language of the Computer (1) | 2024.02.06 |
| 2. The Power wall (0) | 2024.02.06 |