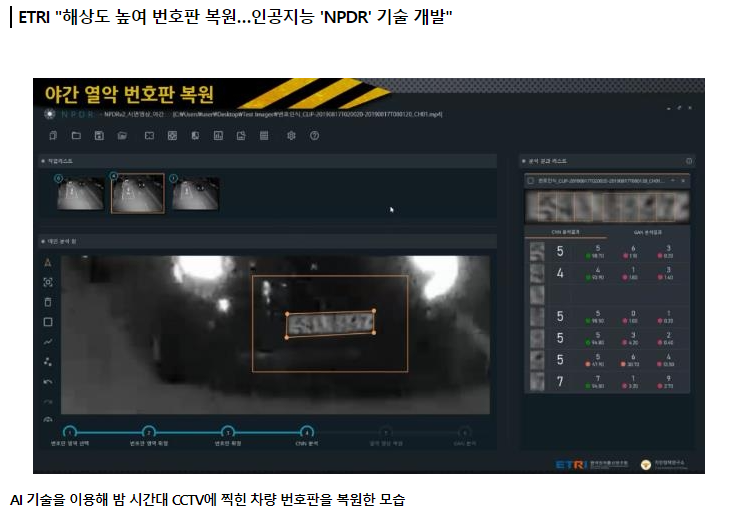
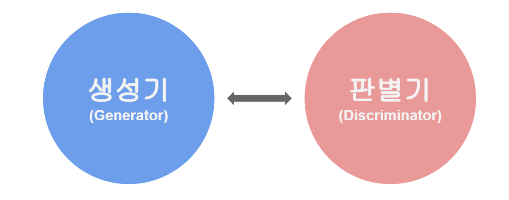
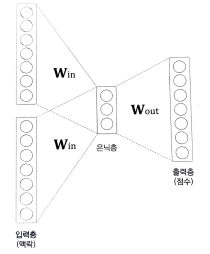
어떤 오브젝트의 텍스처를 인식하는 것은 어려운 문제이고 그 오브젝트의 형태가 정해져 있지 않다면 특히 더 어렵습니다. 빵 같은 경우에는 다양한 형태가 존재하기에 기존에 적용된 object detection 방법으로만은 인식하기 힘들다고 판단했고 다른 방법이 필요하다고 생각이 들었습니다. 비슷한 사업을 진행 중인 기업들을 살펴봤는데 각 기업들은 여러 방향으로 카메라를 달아 depth를 뽑아 3D 모델을 만들어 정확한 개수를 측정했습니다. 하지만 이 경우 여러 대의 카메라가 필요했기에 비용이 높았습니다. 저희 팀의 경우 스마트폰을 사용하여 접근도가 높고 초기 비용이 저렴하다는 경쟁력을 가지고 있기 때문에 해당 방법을 사용하는 것은 힘들다고 생각했습니다. 그렇기에 조금 더 세밀한 텍스처 인식이 가능한 inst..